library(easystats)
library(ggplot2)
library(marginaleffects)
library(qqplotr)
library(sandwich)
data("penguins", "mtcars", "cars", "airquality")
theme_set(theme_bw(base_size = 20))Multilevel Modeling
Linear Modeling Review (2/2)
Spring 2026 | CLAS | PSYC 894
Jeffrey M. Girard | Lecture 02b

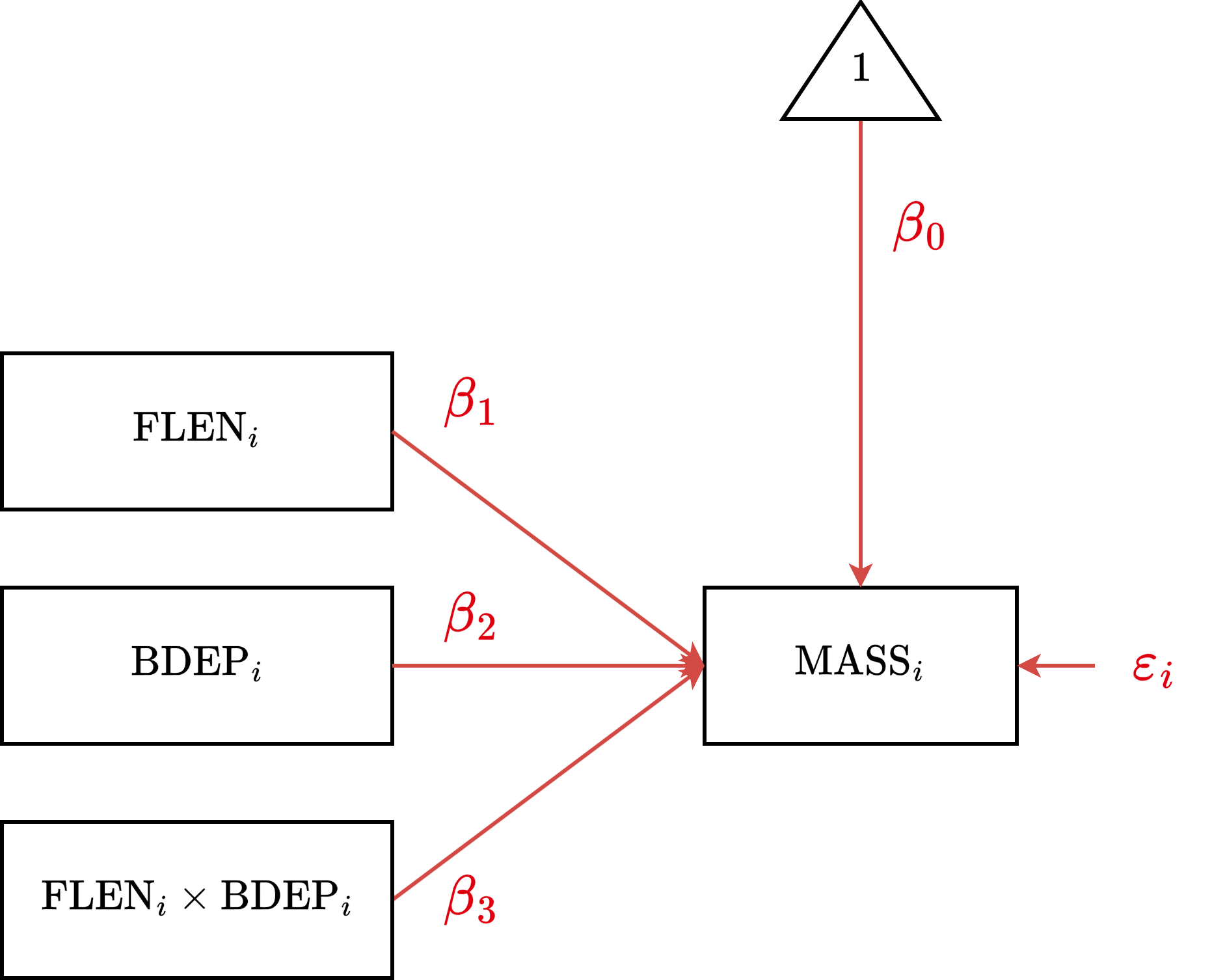
CCM Diagram
CCM Visualization 1
pred_ccmf <- estimate_relation(
model = ccm_fb,
by = c(
"flipper_len",
"bill_dep = [quartiles]"
),
estimate = "average"
)
plot(pred_ccmf) +
labs(
x = "Flipper Length",
y = "Body Mass",
color = "Bill Depth",
fill = "Bill Depth"
) +
theme(legend.position = "top")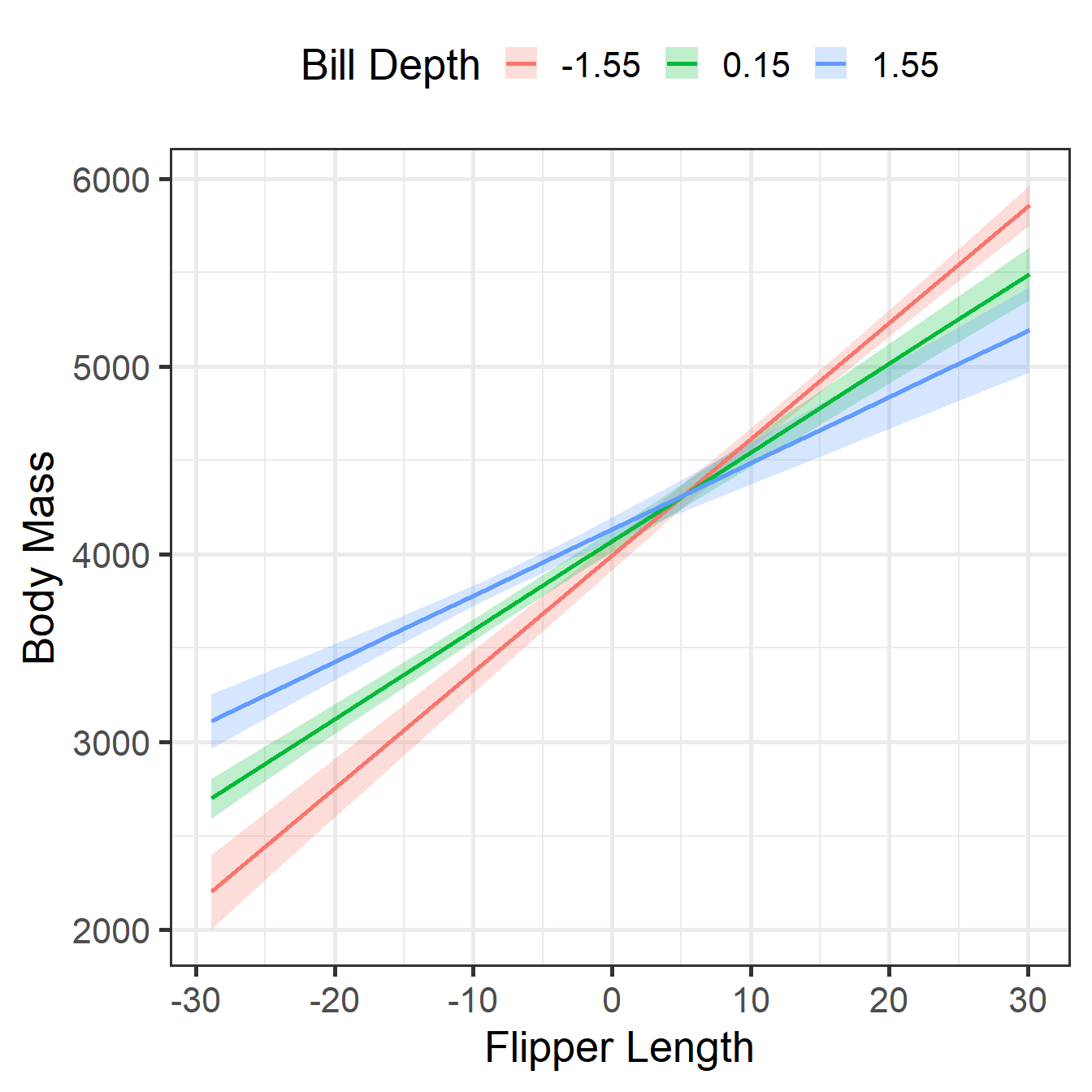
CCM Visualization 2
pred_ccmb <- estimate_relation(
model = ccm_fb,
by = c(
"bill_dep",
"flipper_len = [quartiles]"
),
estimate = "average"
)
plot(pred_ccmb) +
labs(
x = "Bill Depth",
y = "Body Mass",
color = "Flipper Length",
fill = "Flipper Length"
) +
theme(legend.position = "top")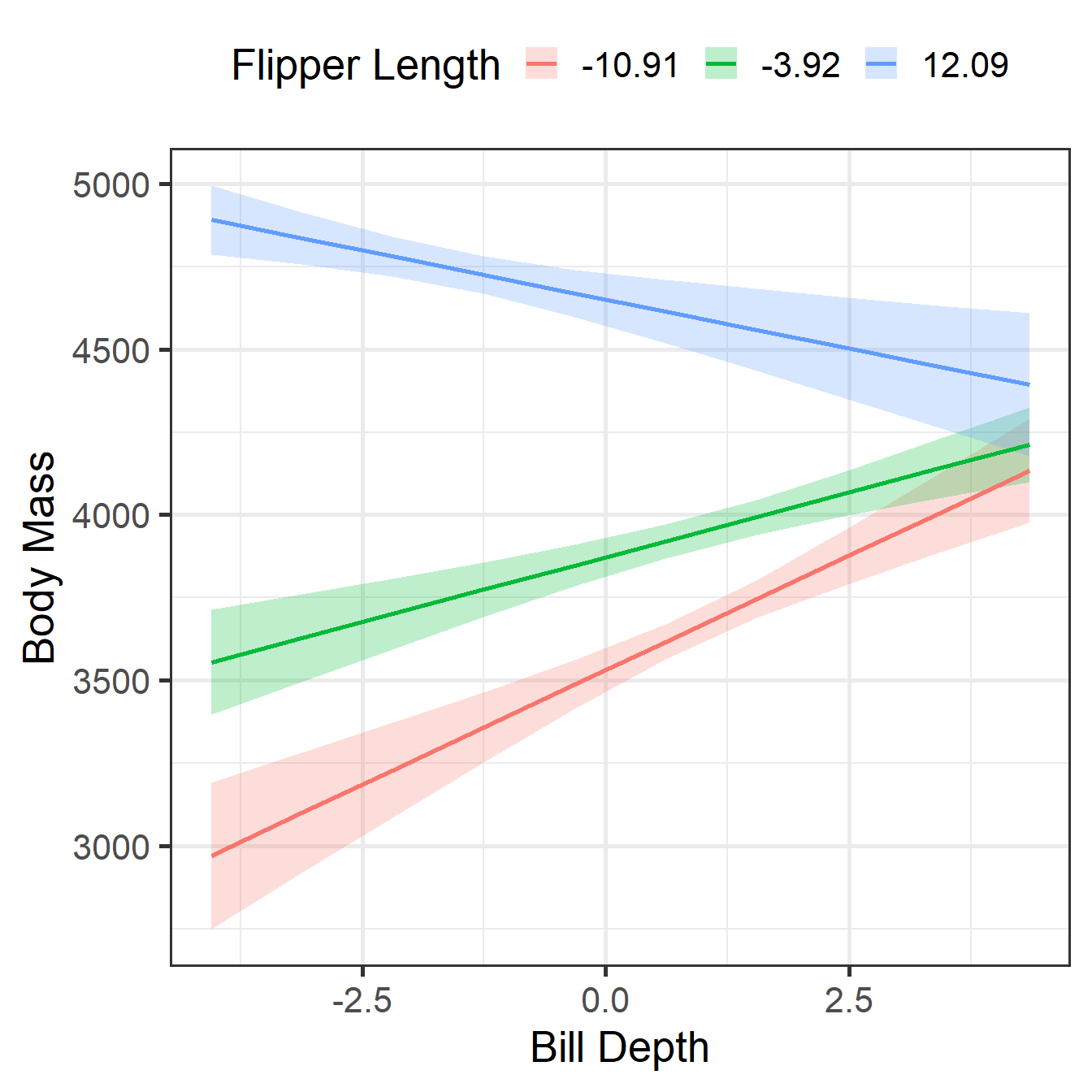
CDM Diagram
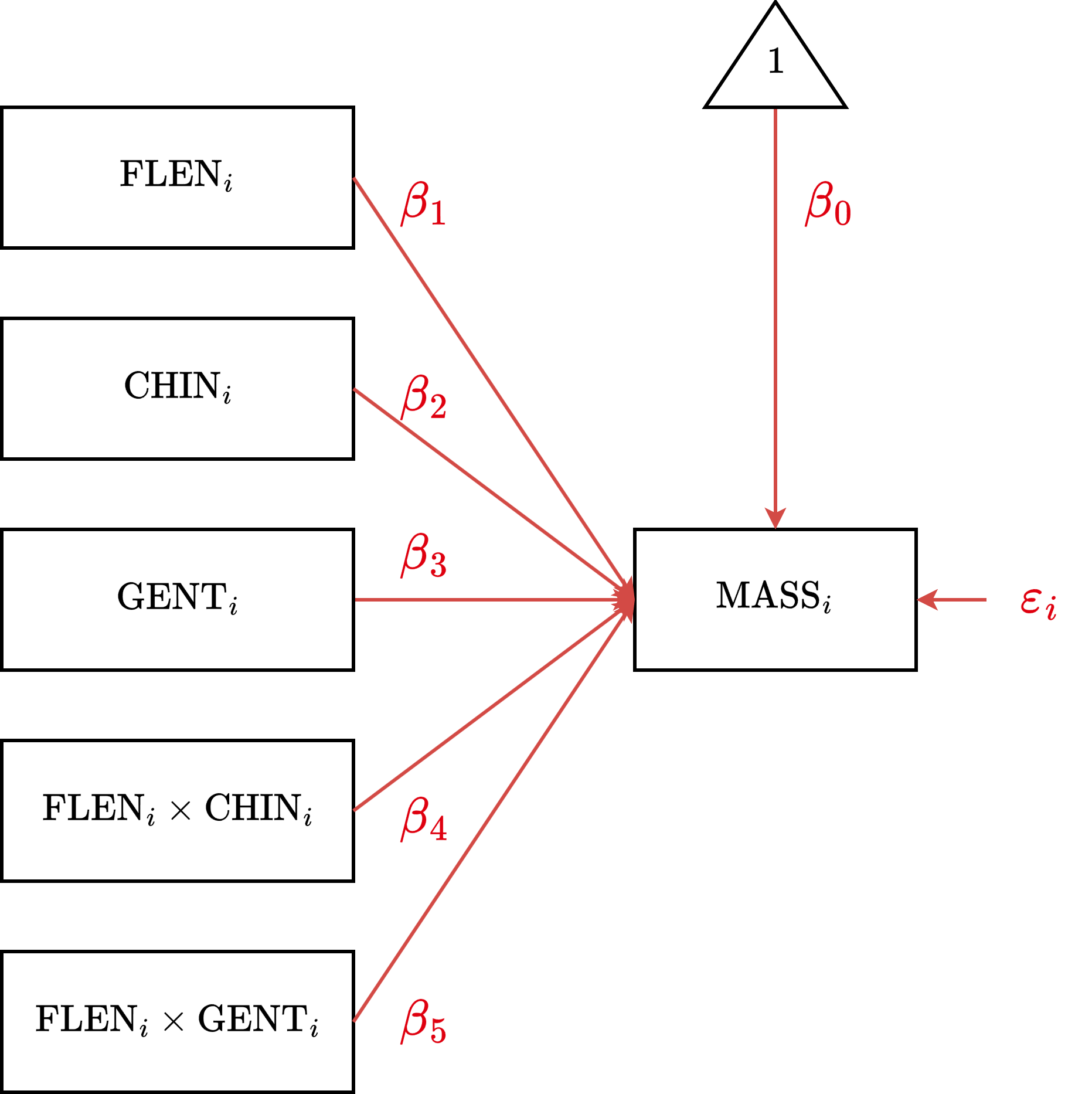
CDM Visualization
pred_cdmf <- estimate_relation(
model = cdm_fs,
by = c(
"flipper_len",
"species"
),
estimate = "average"
)
plot(pred_cdmf) +
labs(
x = "Flipper Length",
y = "Body Mass",
color = "Species",
fill = "Species"
) +
theme(legend.position = "top")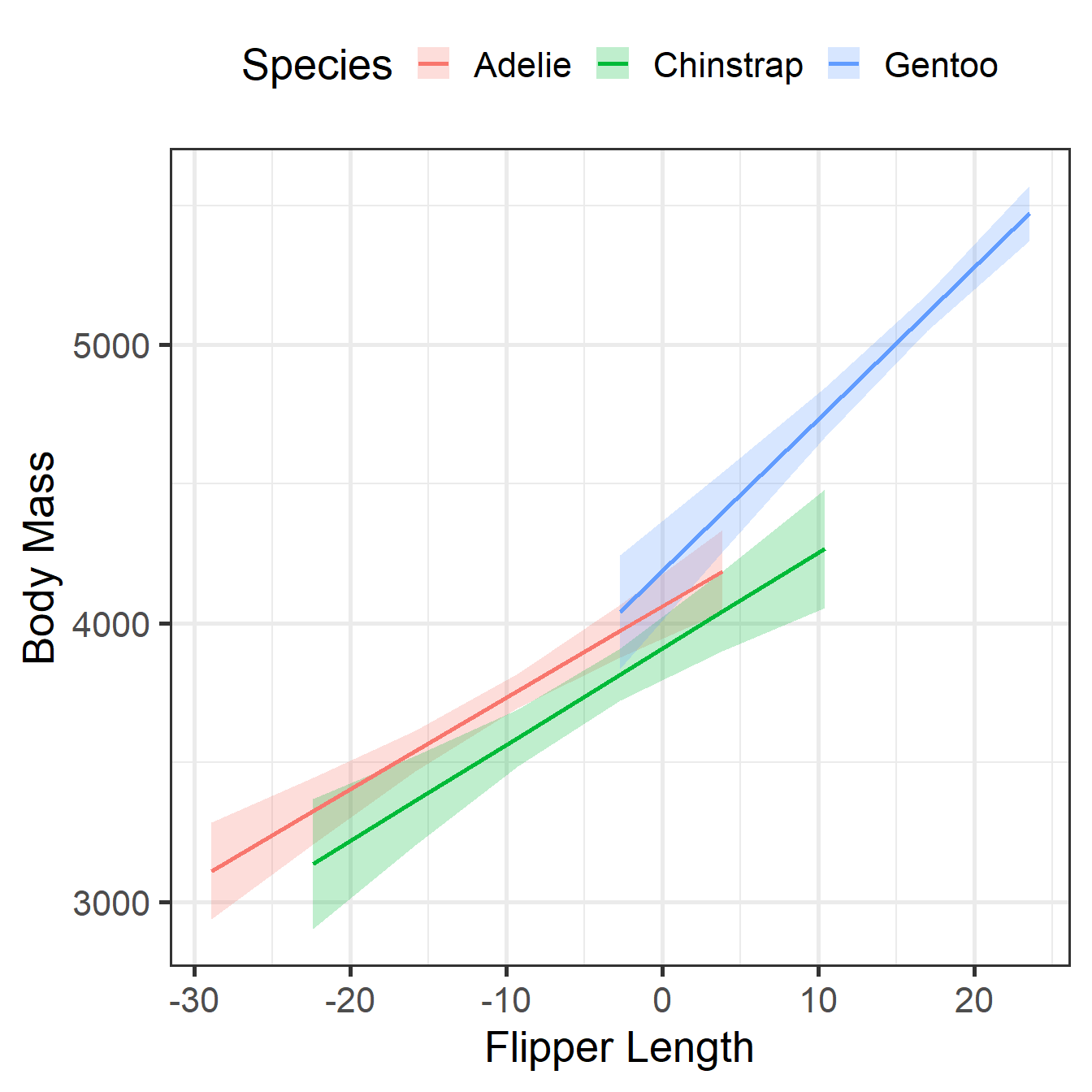
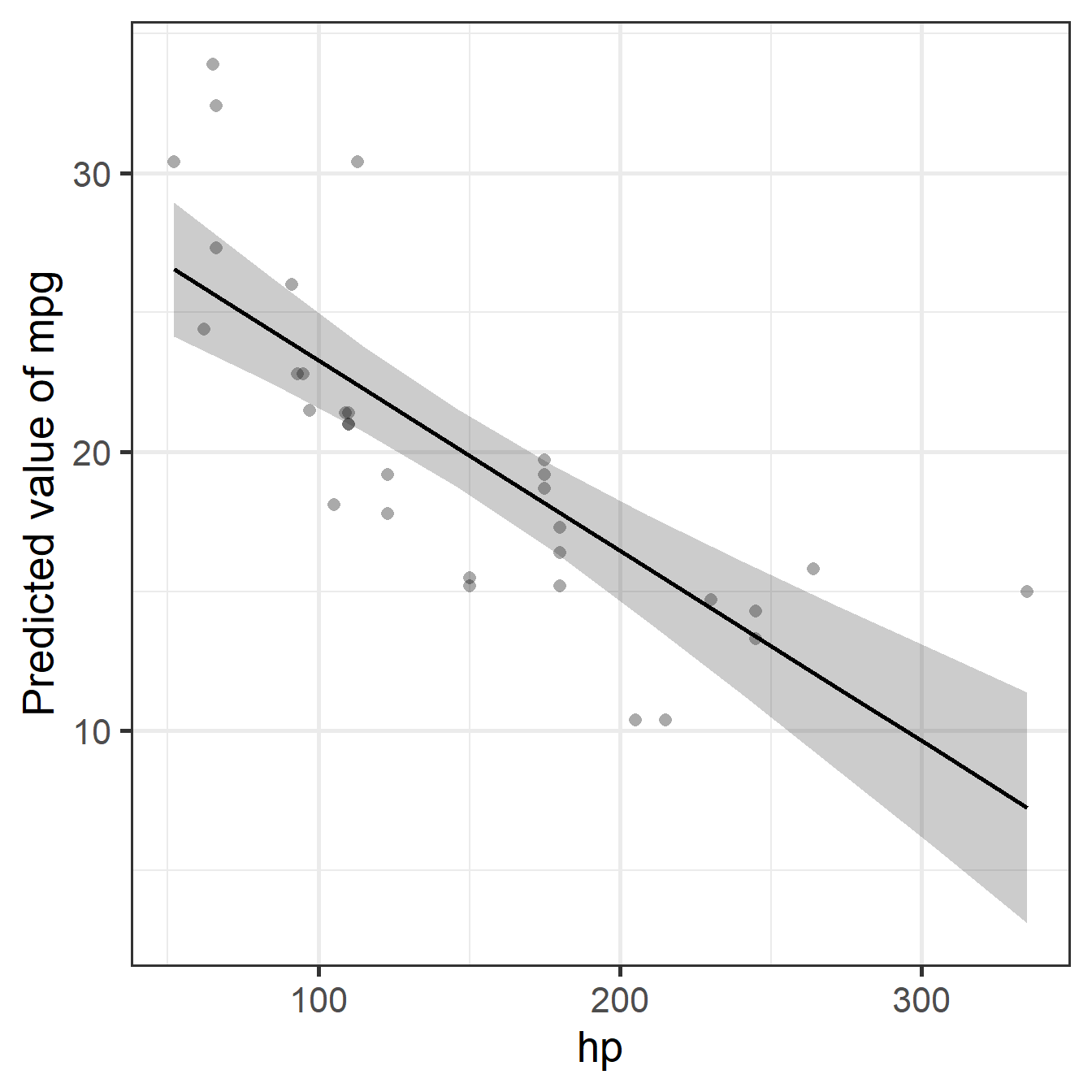
Example
# Does horsepower predict mpg?
fit_line <- lm(
formula = mpg ~ 1 + hp,
data = mtcars
)
pred_line <- estimate_relation(
model = fit_line,
by = "hp"
)
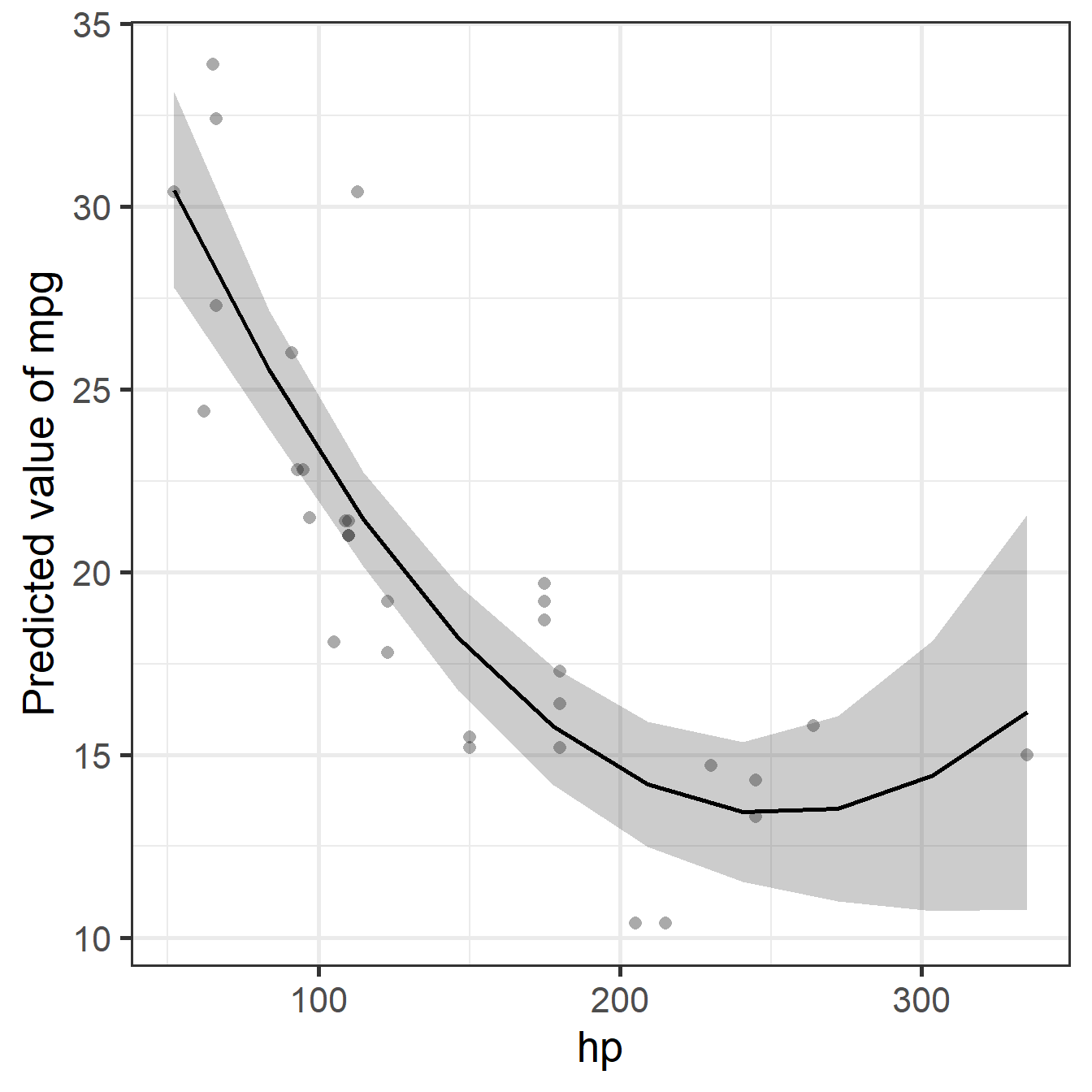
plot(pred_line, show_data = TRUE)Note: Adding horsepower hurts fuel economy, but this levels off (you can’t go below 0 mpg), creating the curve that the linear model misses.
Diagnostic
# The reference line looks bad - major violation
check_model(fit_line, check = "linearity", base_size = 16)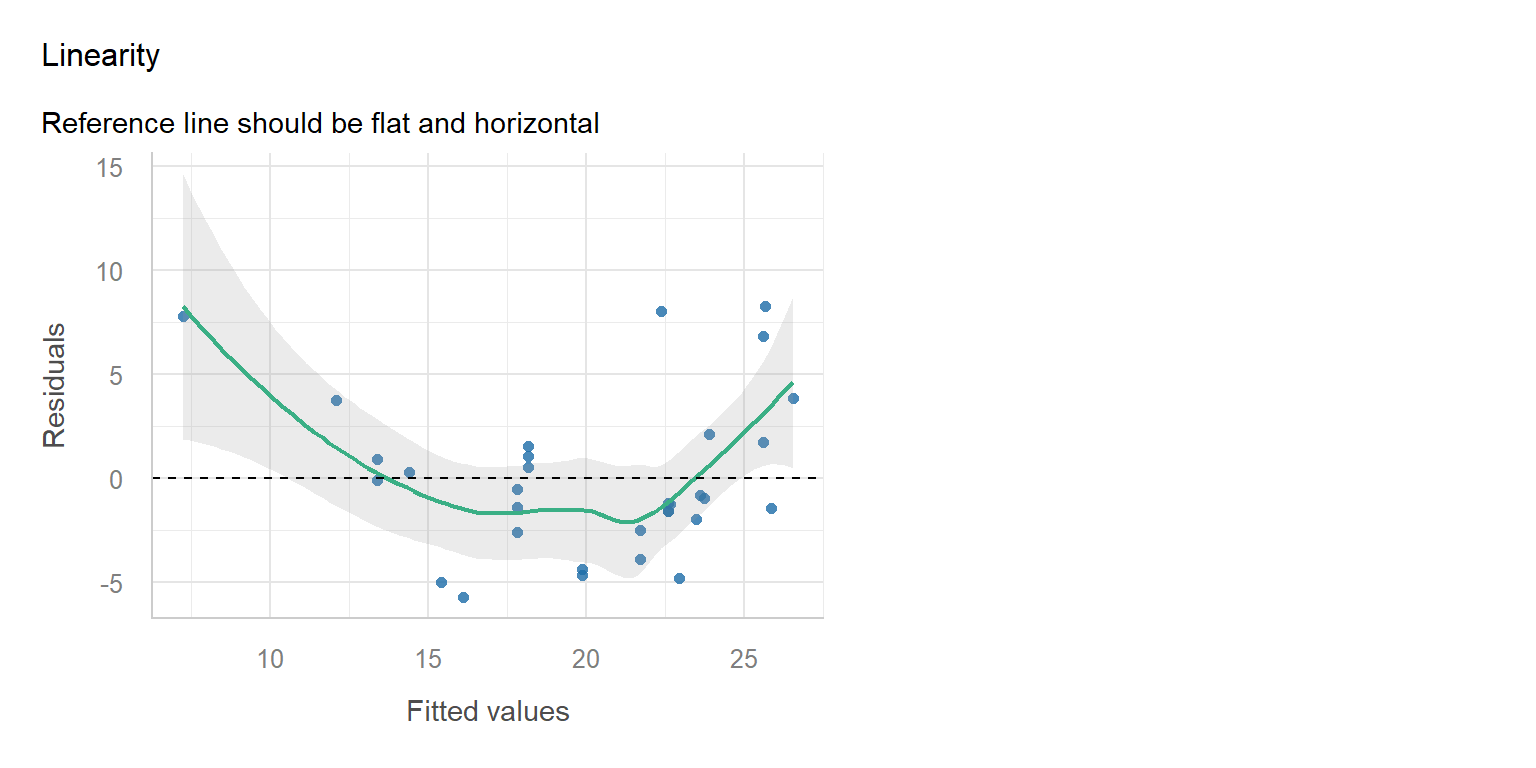
Implementation
fit_poly <- lm(
formula = mpg ~ 1 +
poly(hp, 2, raw = TRUE),
data = mtcars
)
pred_poly <- estimate_relation(
model = fit_poly,
by = "hp"
)
plot(pred_poly, show_data = TRUE)Note: By allowing the line to bend or curve (quadratically), we capture the relationship accurately.
Example
# Does speed predict stop distance?
fit_cars <- lm(
formula = dist ~ speed,
data = cars
)
pred_cars <- estimate_relation(
fit_cars,
by = "speed"
)
plot(pred_cars, show_data = TRUE)Note: At low speeds, points are near the line. At high speeds, they spread out. We predict distance for “slow” stops well, but not for “fast” stops.
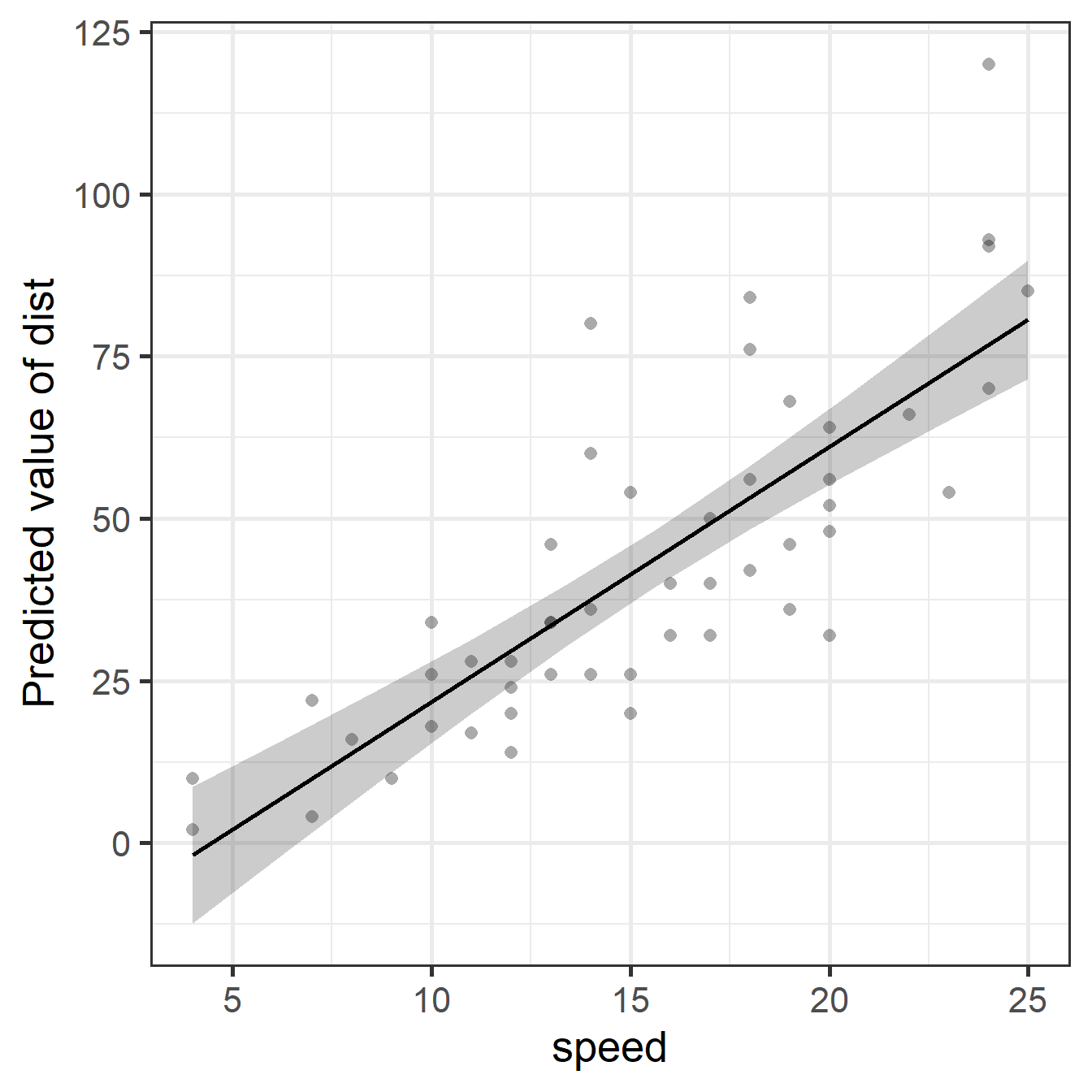
Diagnostic
# The reference line looks fair - minor violation
check_model(fit_cars, check = "homogeneity", base_size = 16)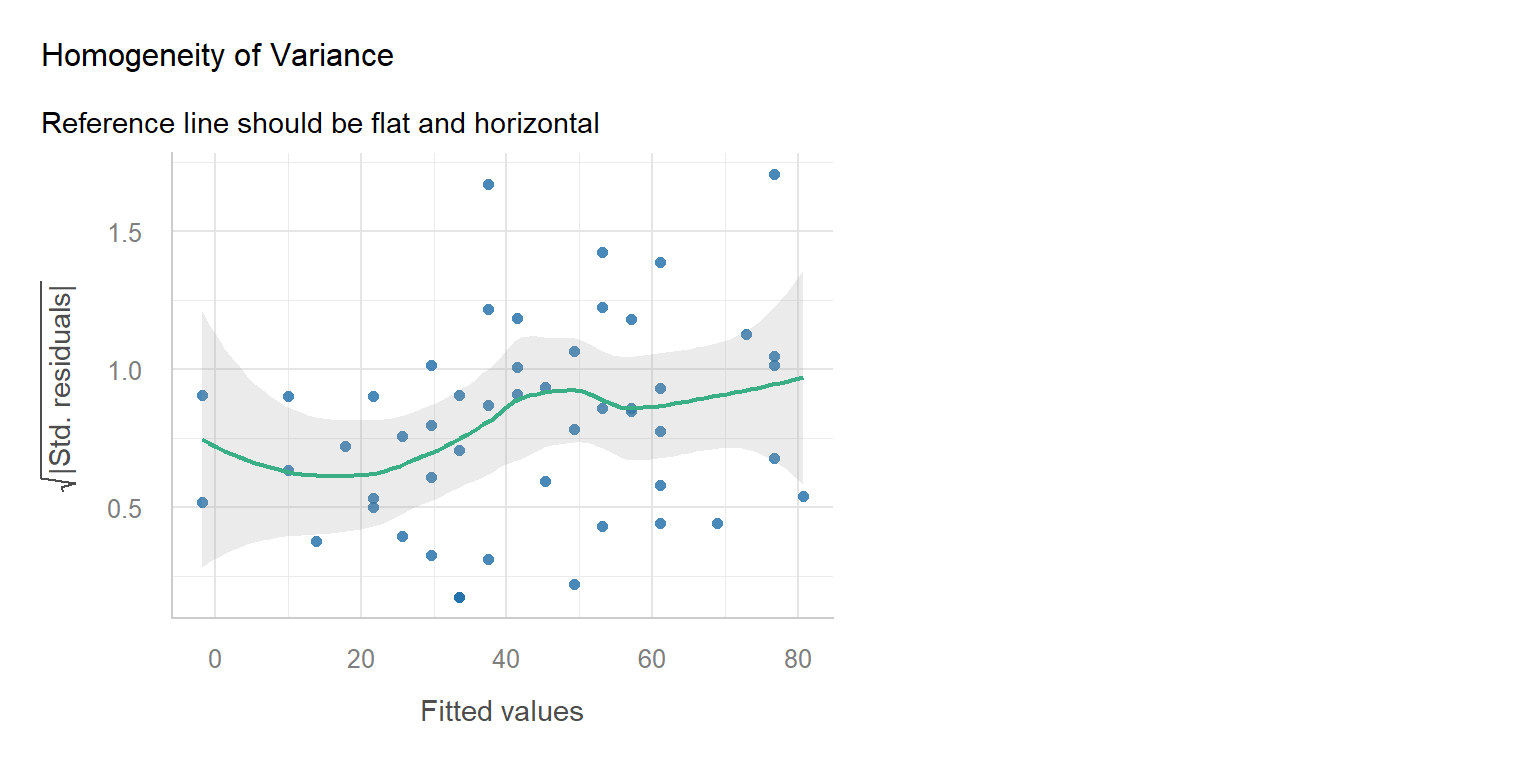
Example
# Does wind speed predict ozone?
fit_ozone <- lm(
formula = Ozone ~ Wind,
data = airquality
)
pred_ozone <- estimate_relation(
model = fit_ozone,
by = "Wind"
)
plot(pred_ozone, show_data = TRUE)Note: The model fits a straight line, but there are outliers and negative Ozone (impossible) is being predicted.
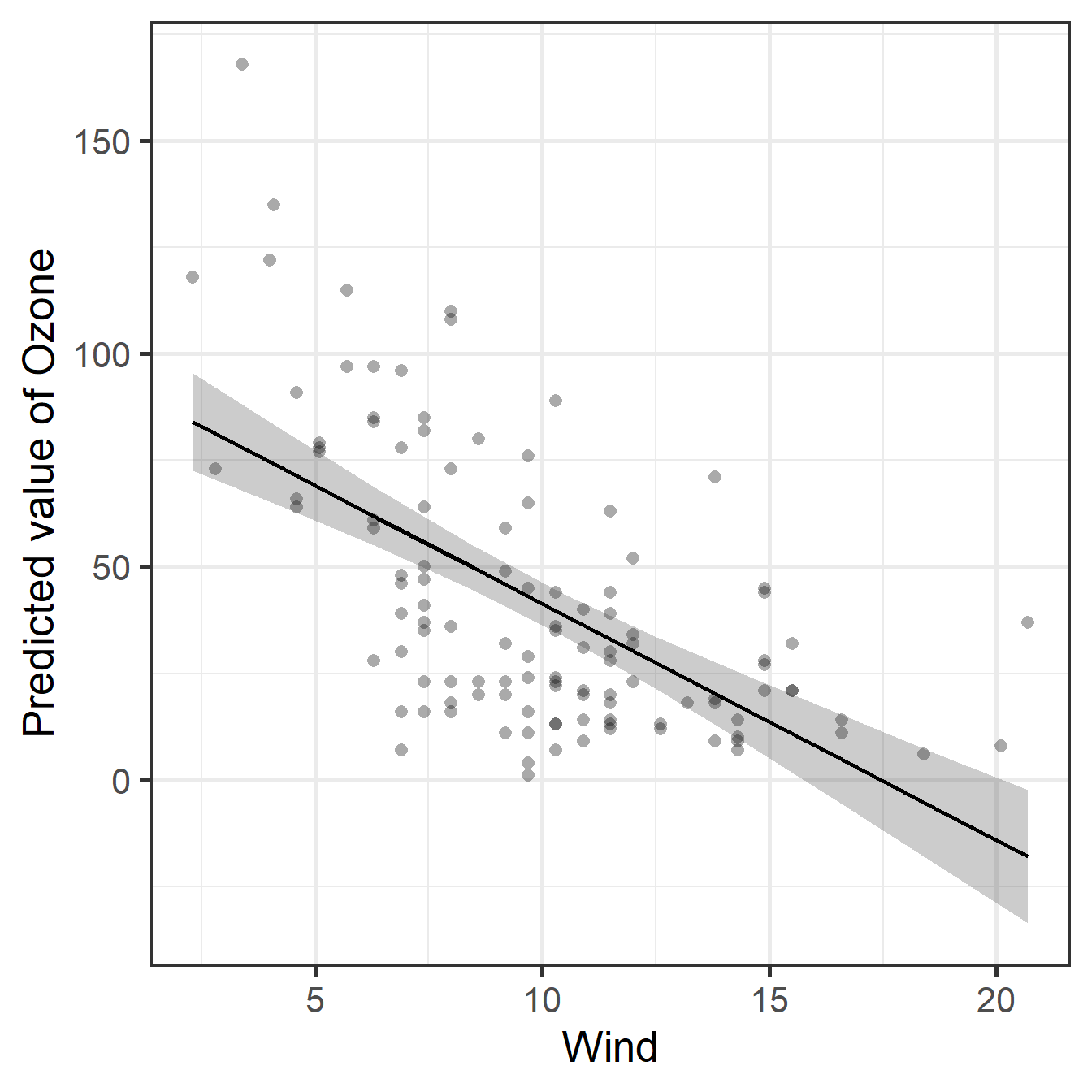
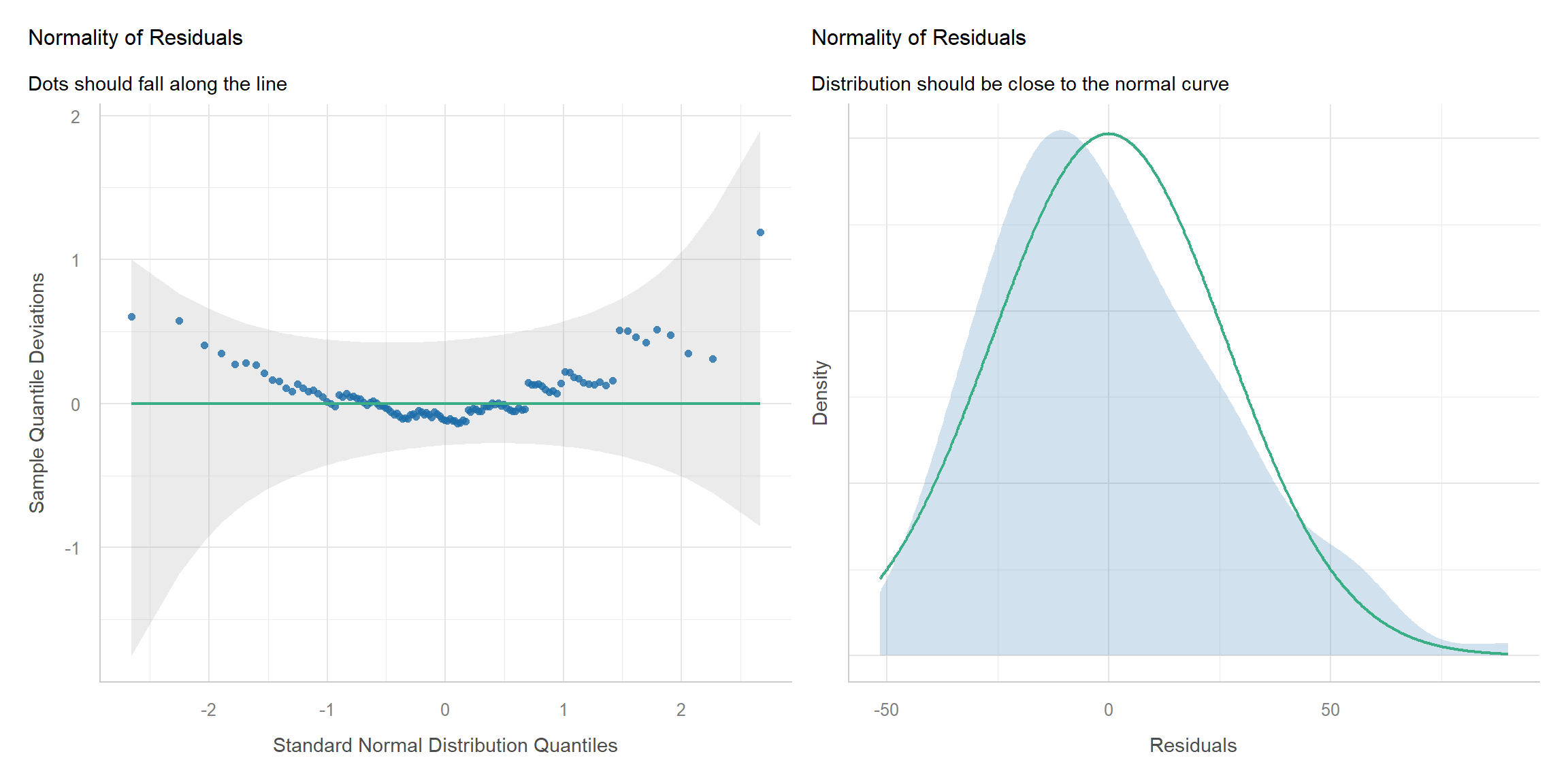
Diagnostic
# Distributions look fair - minor violation
check_model(fit_ozone, check = c("qq", "normality"), base_size = 18)