Multilevel Modeling
Estimation Strategies
Spring 2026 | CLAS | PSYC 894
Jeffrey M. Girard | Lecture 04a

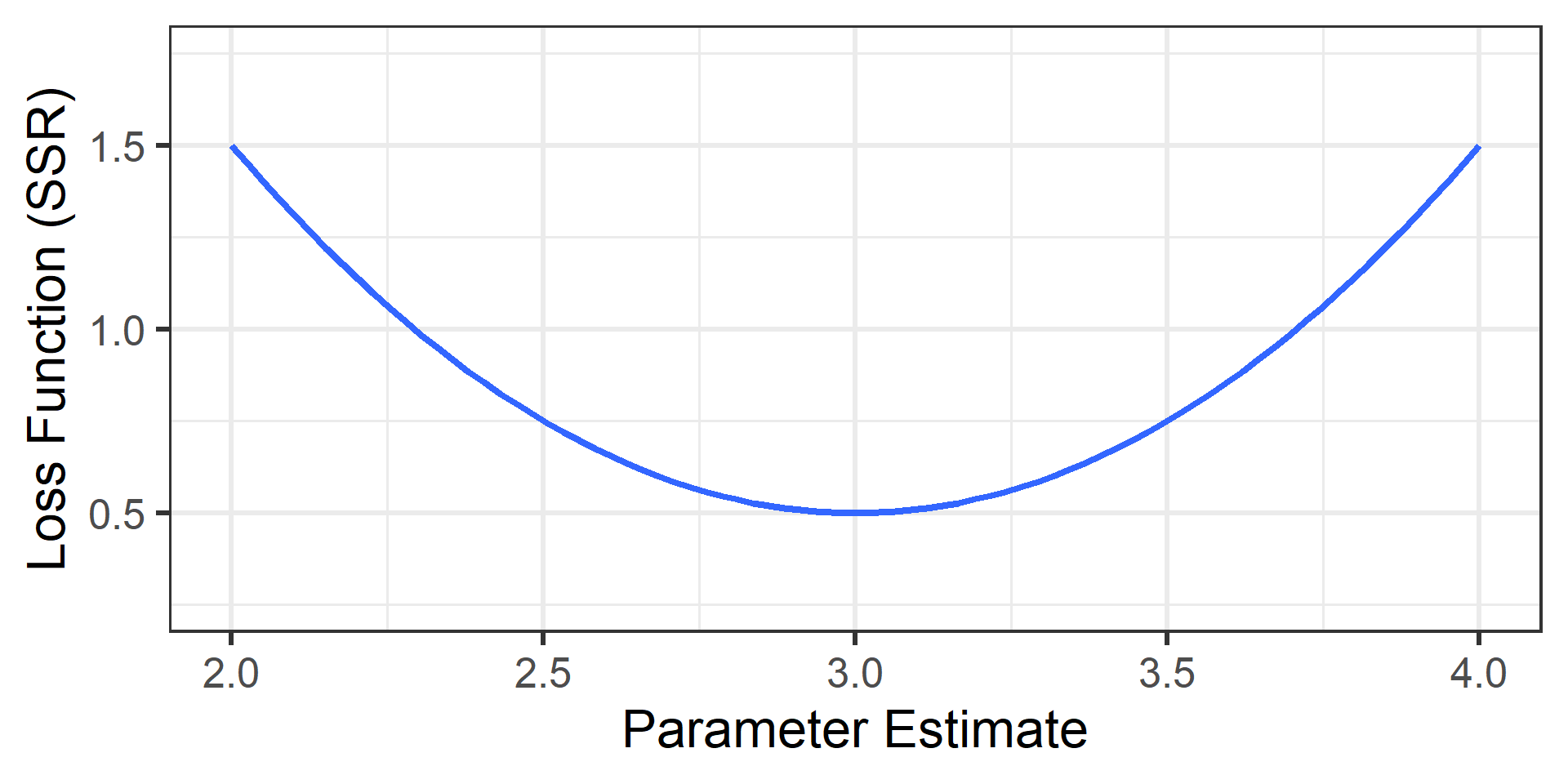
Loss Function
Here is our imagined plot when the true value is \(\beta=3.0\)
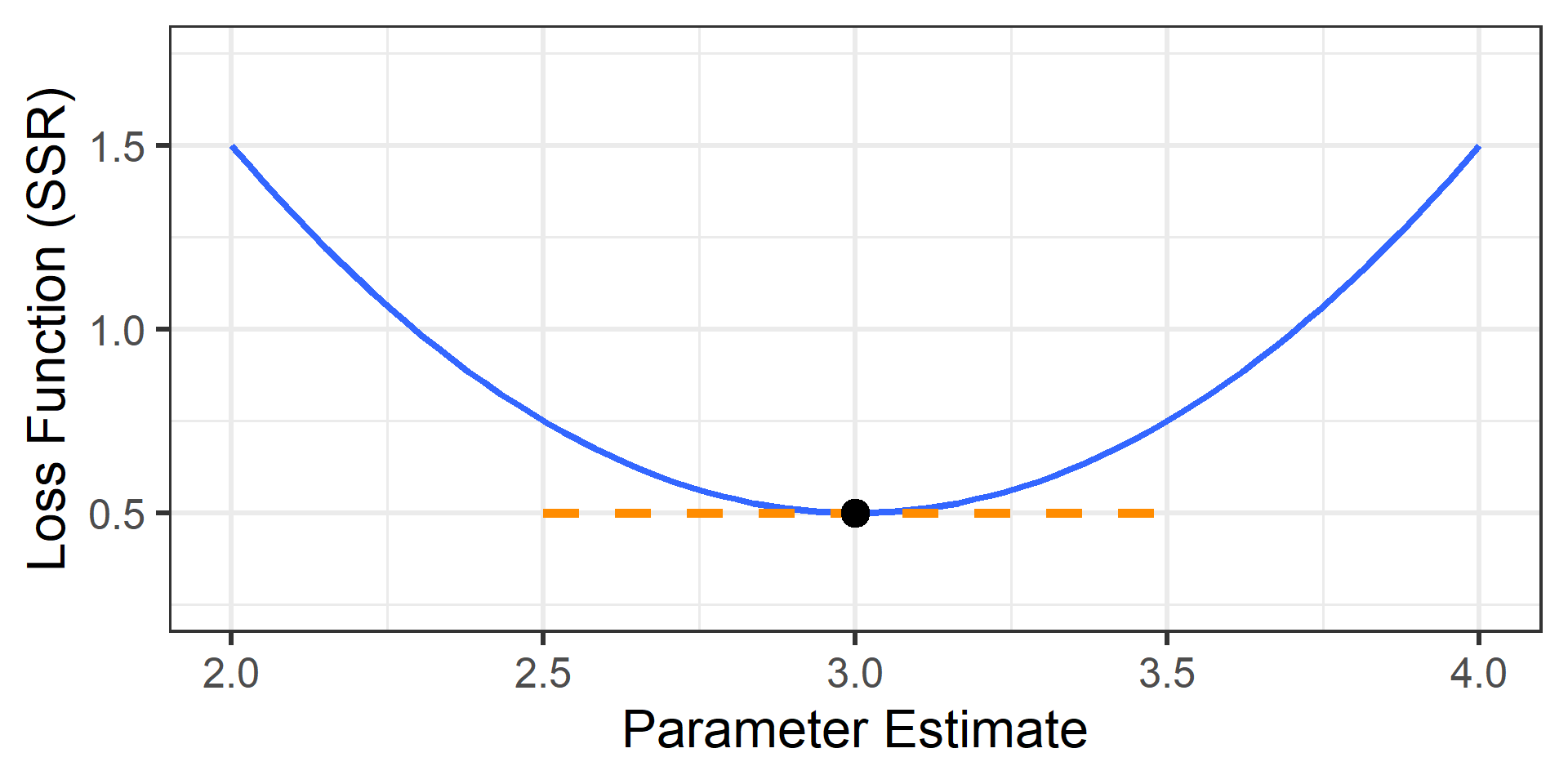
Derivative at Zero
The derivative is the slope of the tangent line
Visual Example
We start with no knowledge of the likelihood function
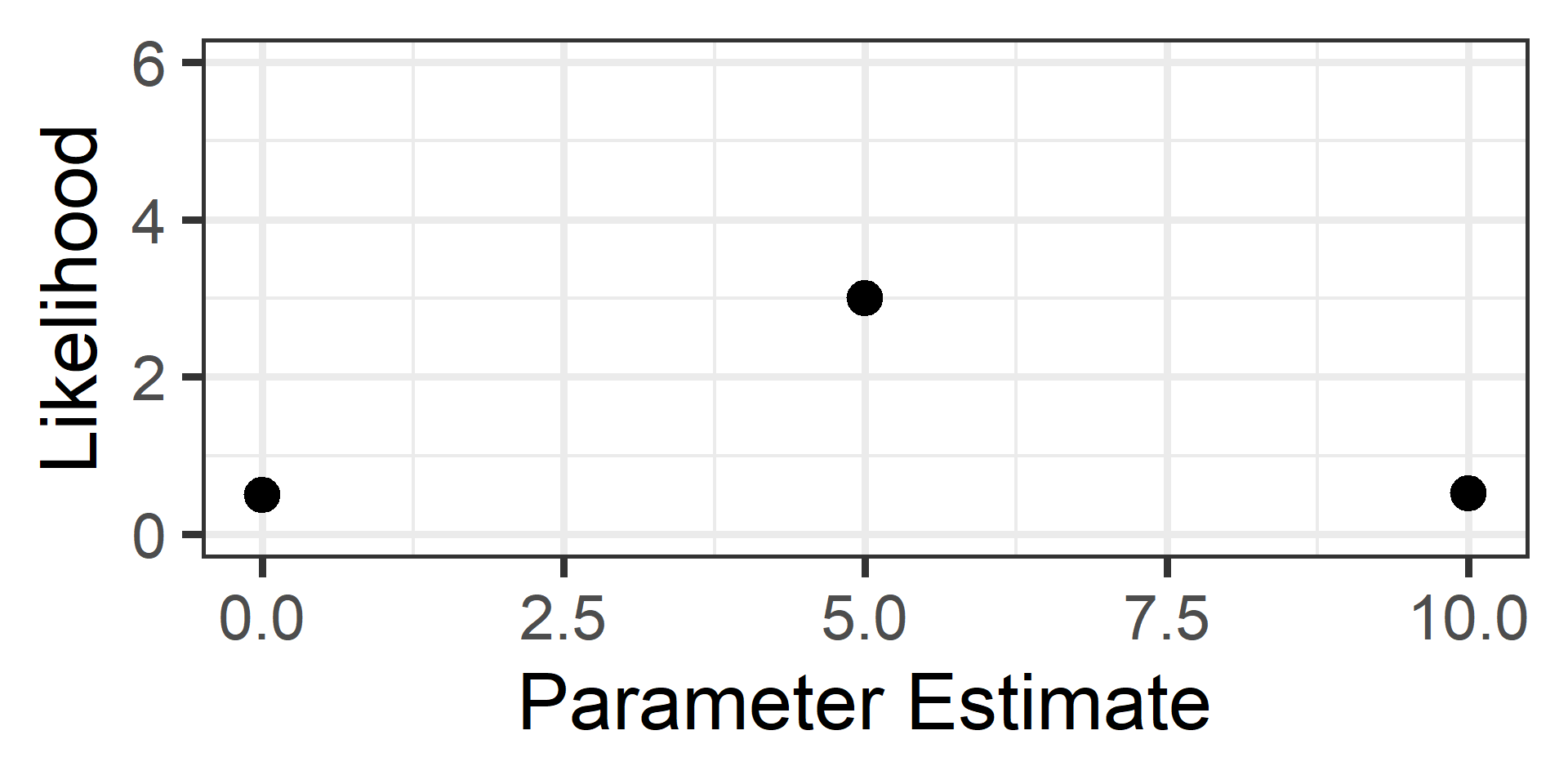
Visual Example 2
We can choose three starting values at \(x=\{0,5,10\}\)
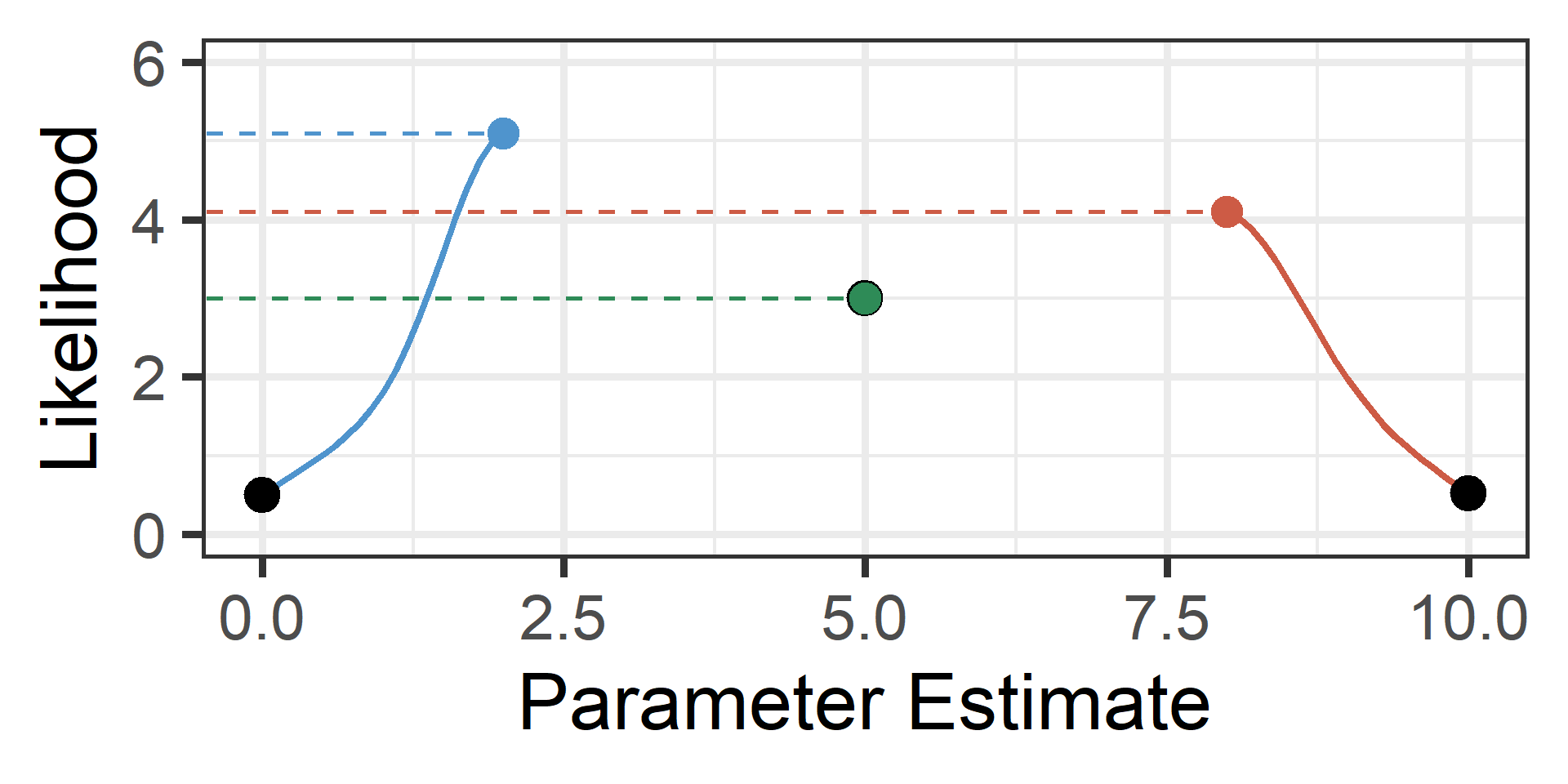
Visual Example 2
Now each climbs until convergence and the highest wins
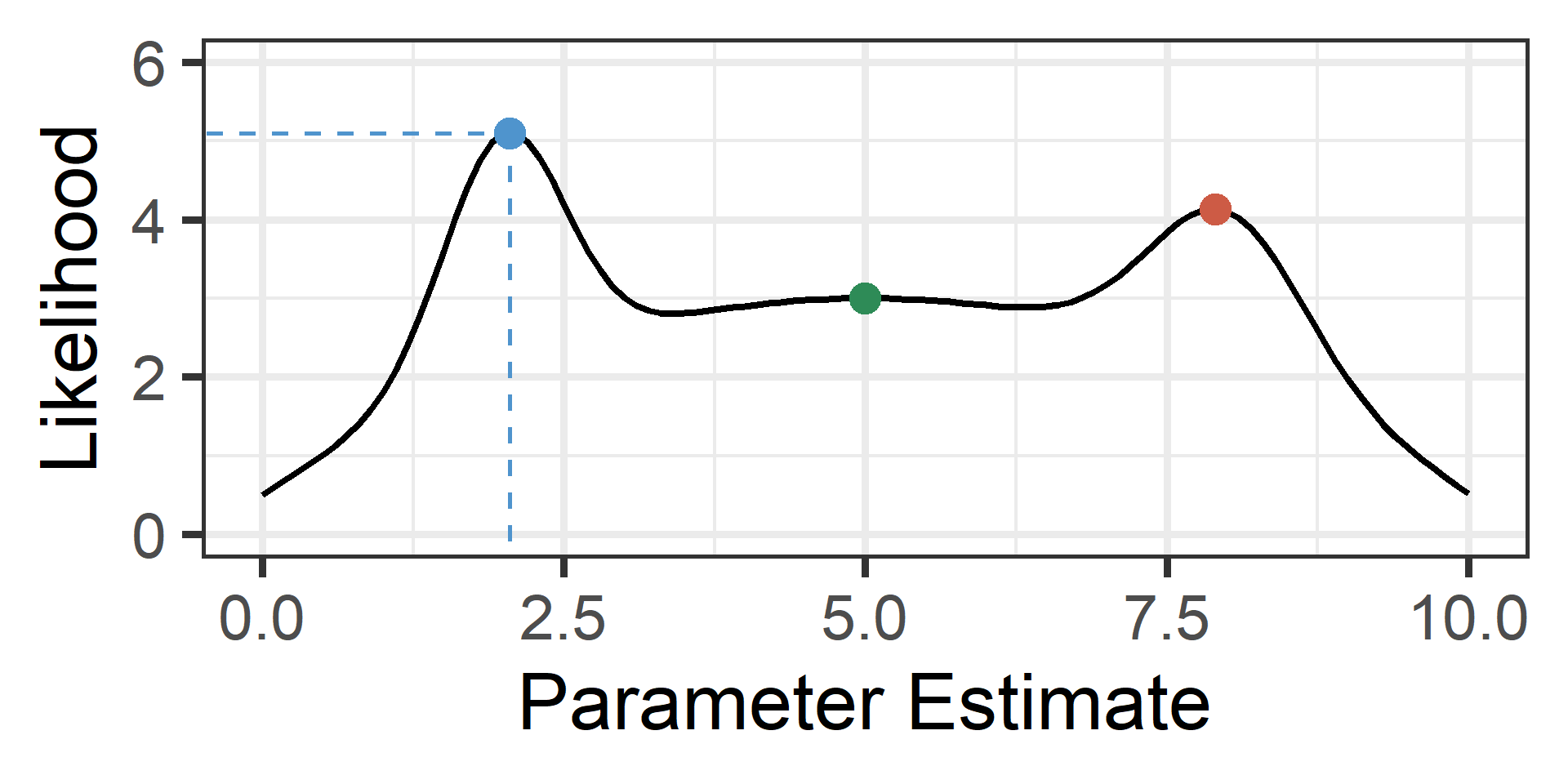
Visual Example 3
The unknown-to-us likelihood function is plotted in black
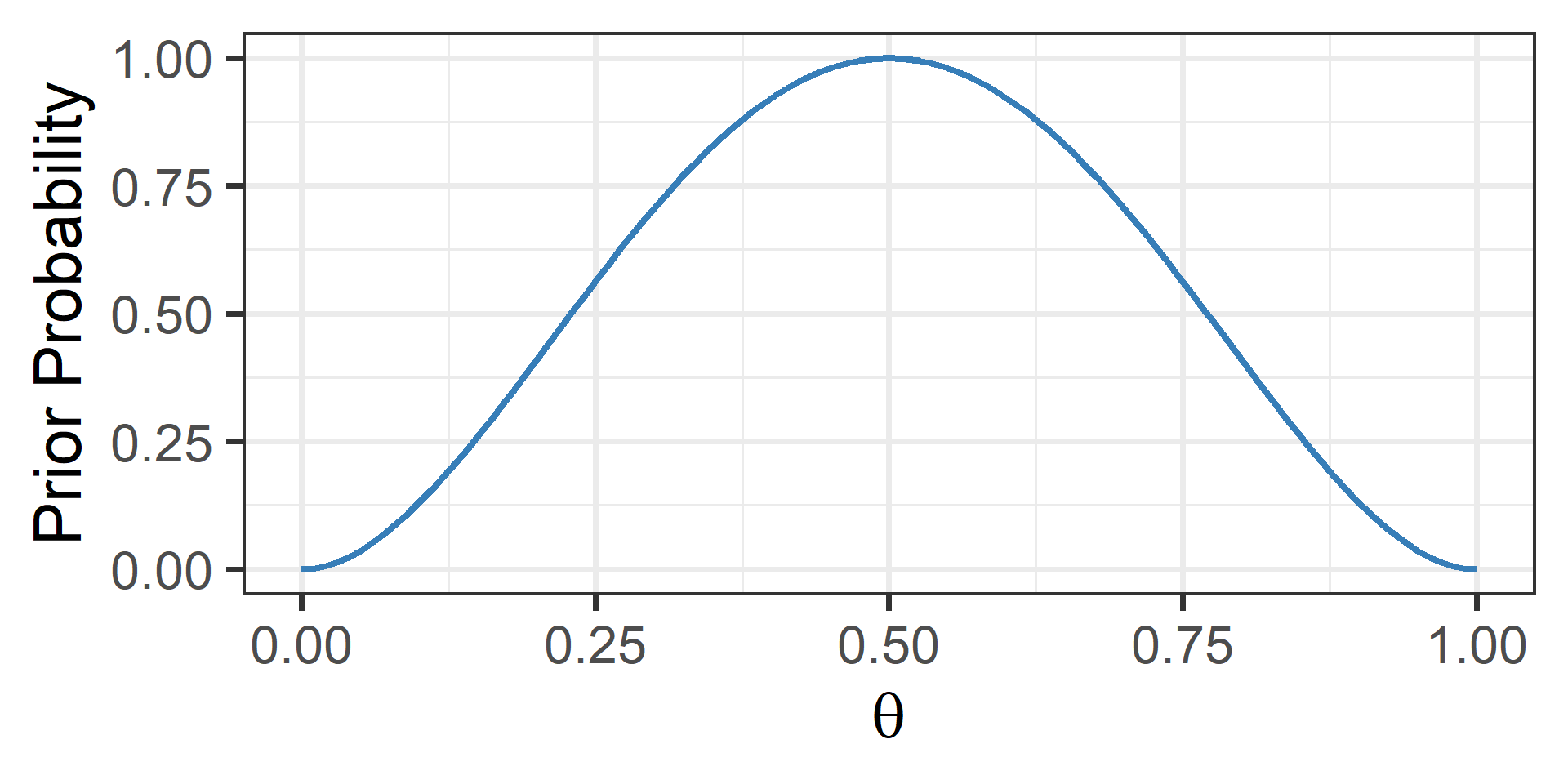
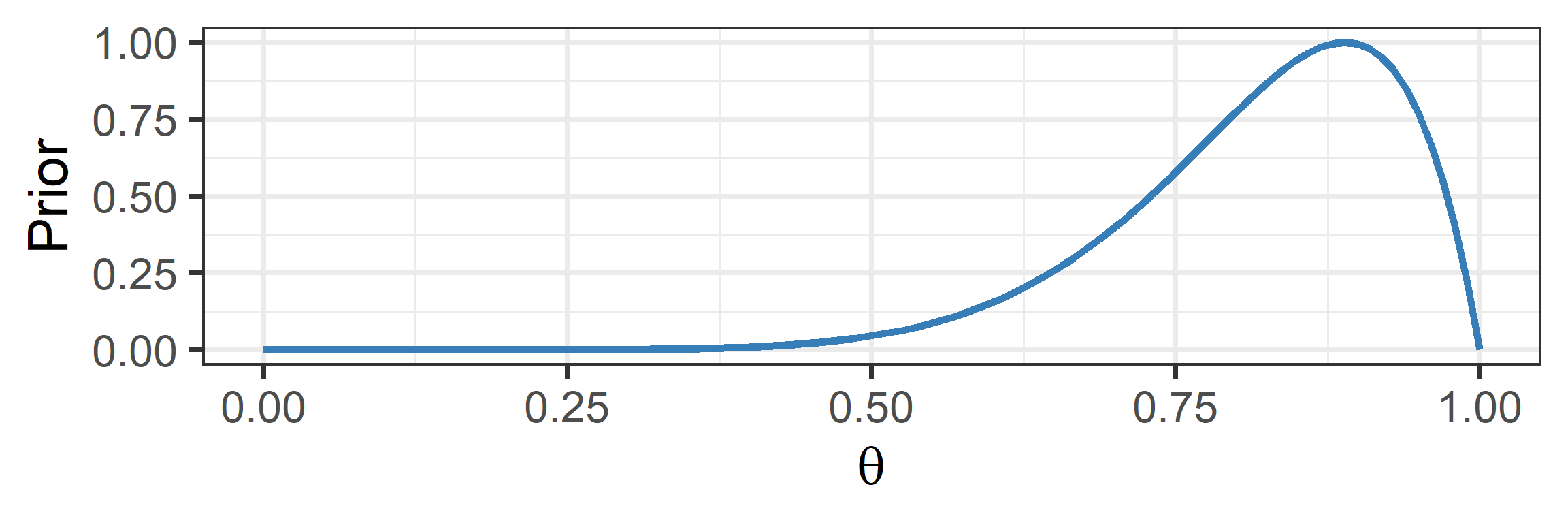
Visual Depiction: Prior
Visual Depiction: Likelihood
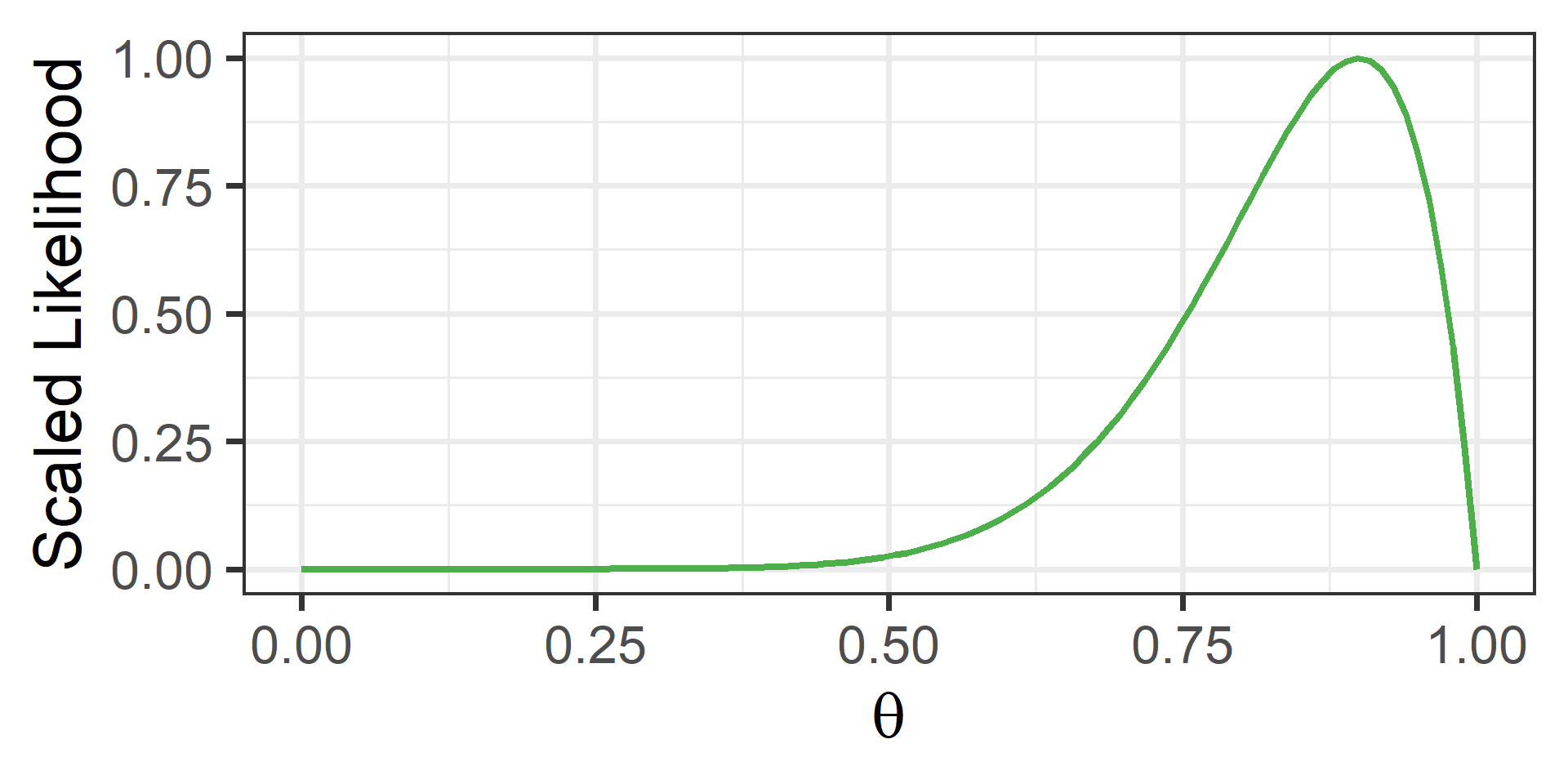
Visual Depiction: Posterior
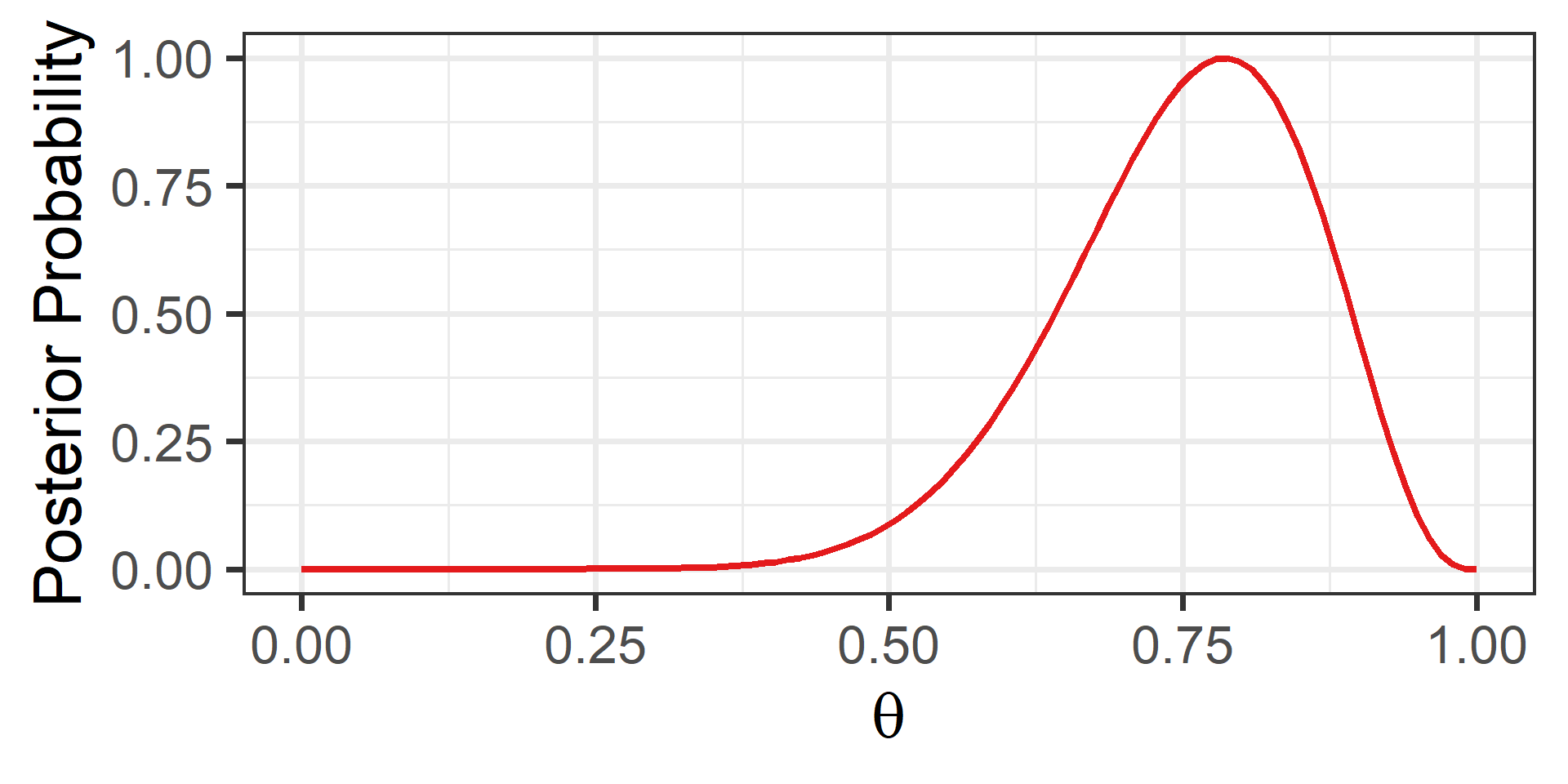
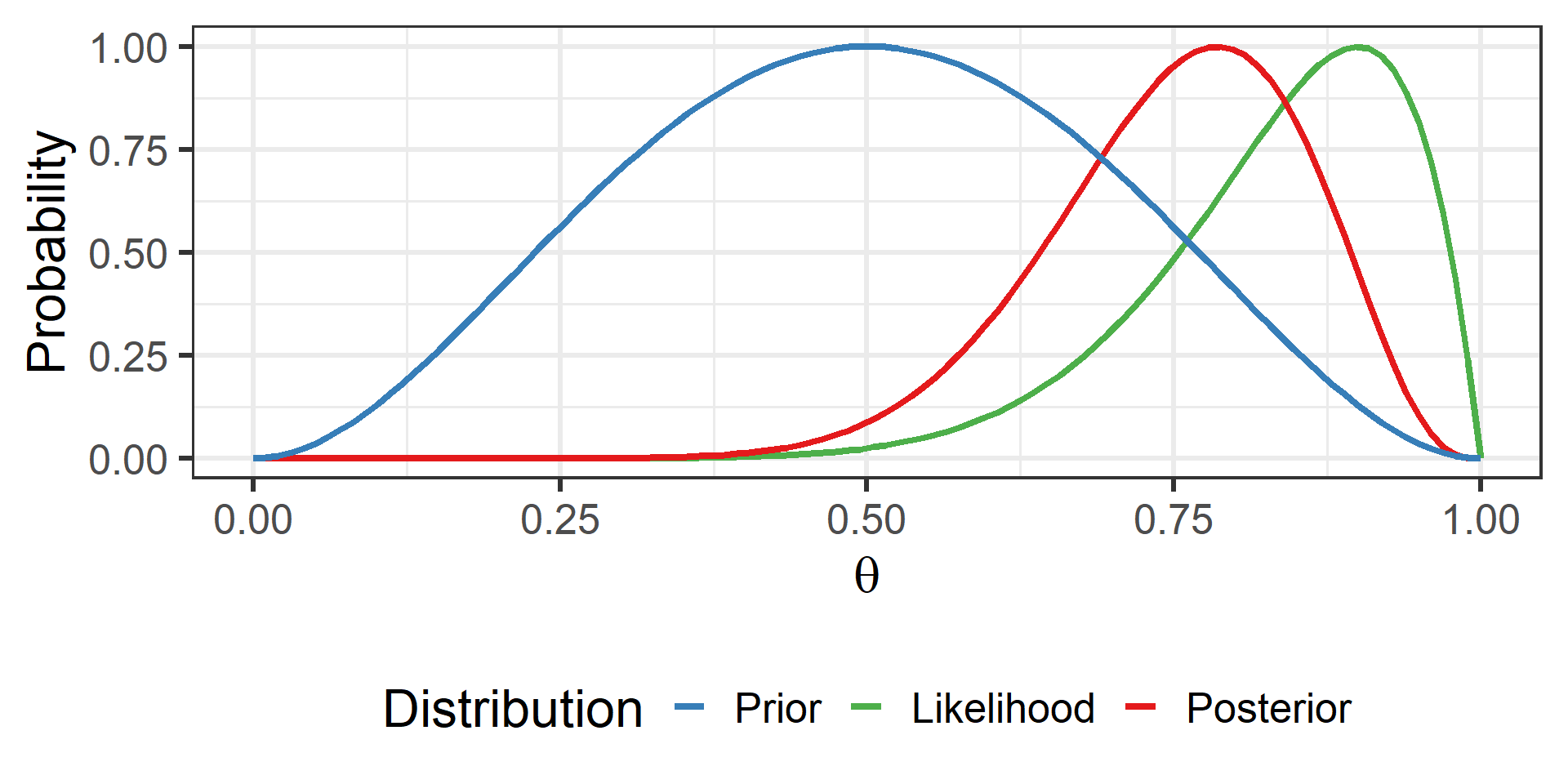
Comparison
Informative Priors
- An informative prior: specific values are more likely
- This can stabilize estimates in small samples
- But can be misleading and needs to be justified
Noninformative Priors
- A noninformative prior: all values are equally likely
- This can yield estimates very similar to MLE
- But some values are really implausible…
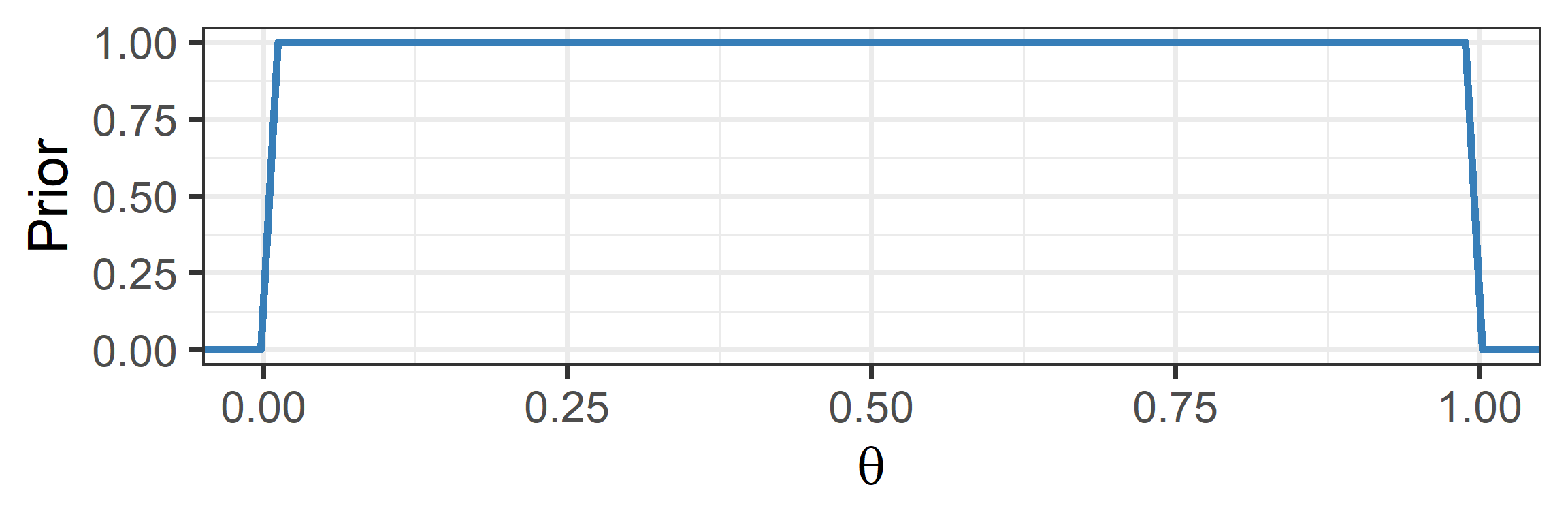
Weakly Informative Priors
- A weakly informative prior: plausible values are more likely
- We can discourage the model from implausible values
- We can conservatively center it on the null value
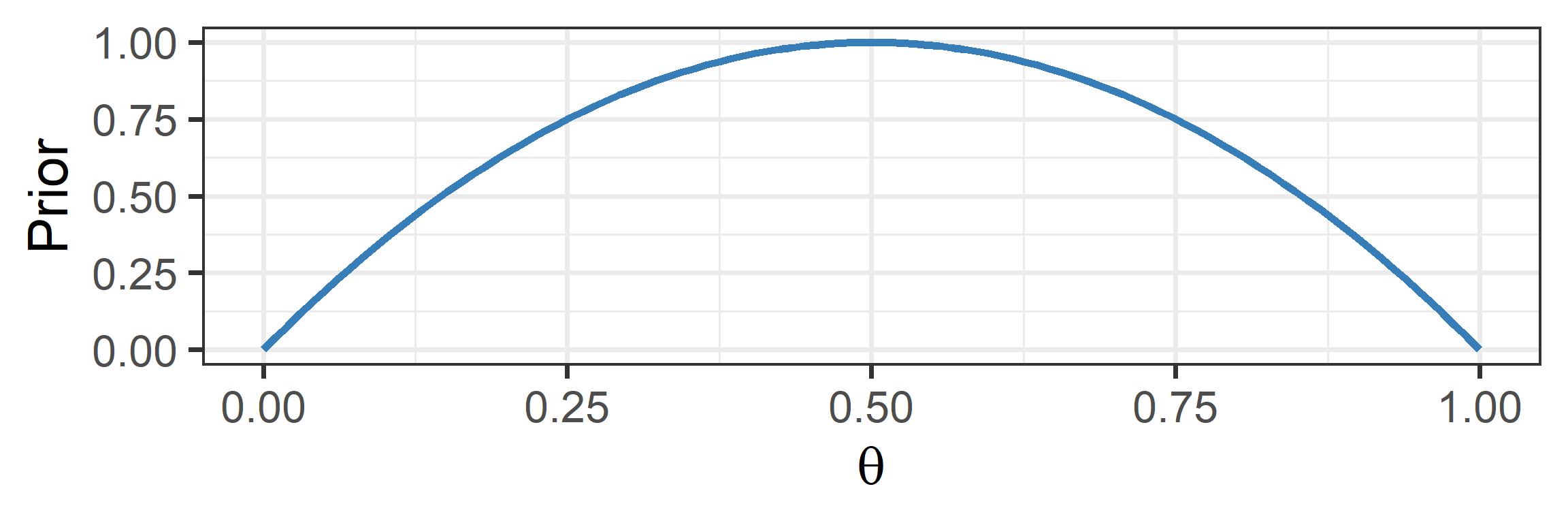
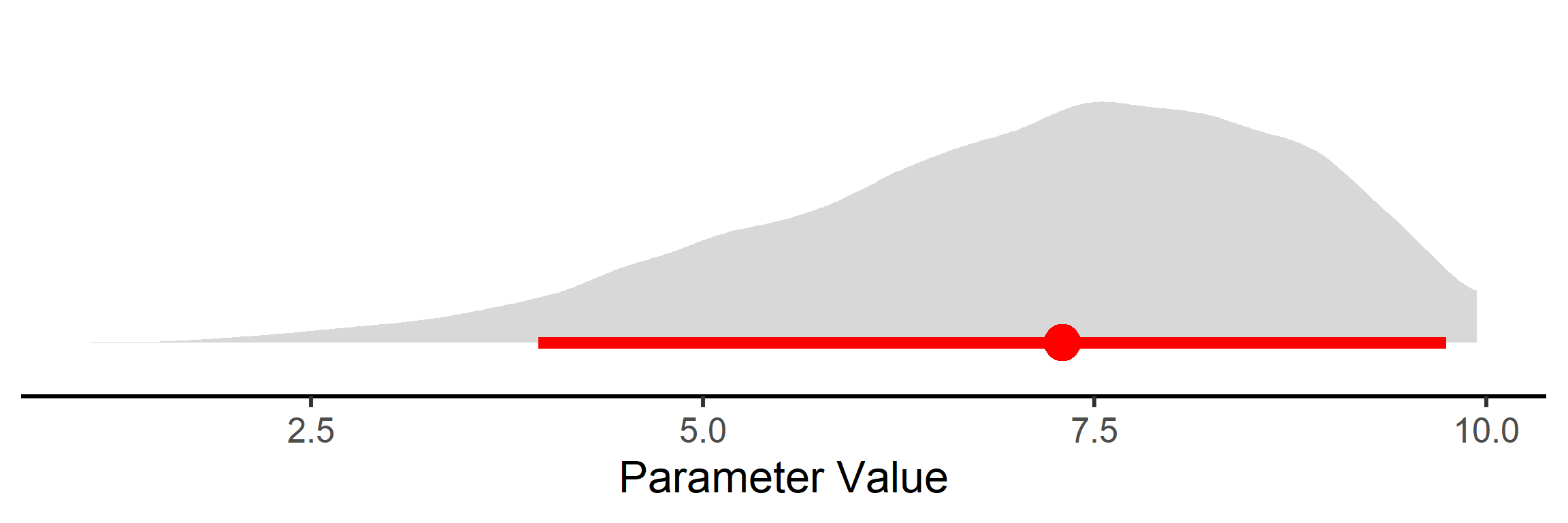
Using the Posterior
1. Point Estimate
We report the center of the posterior distribution (e.g., the Median) as our single “best guess” for the parameter.
2. Uncertainty Interval
We report the interval containing the inner 95% of the posterior density (e.g., the HDI) to show our uncertainty.