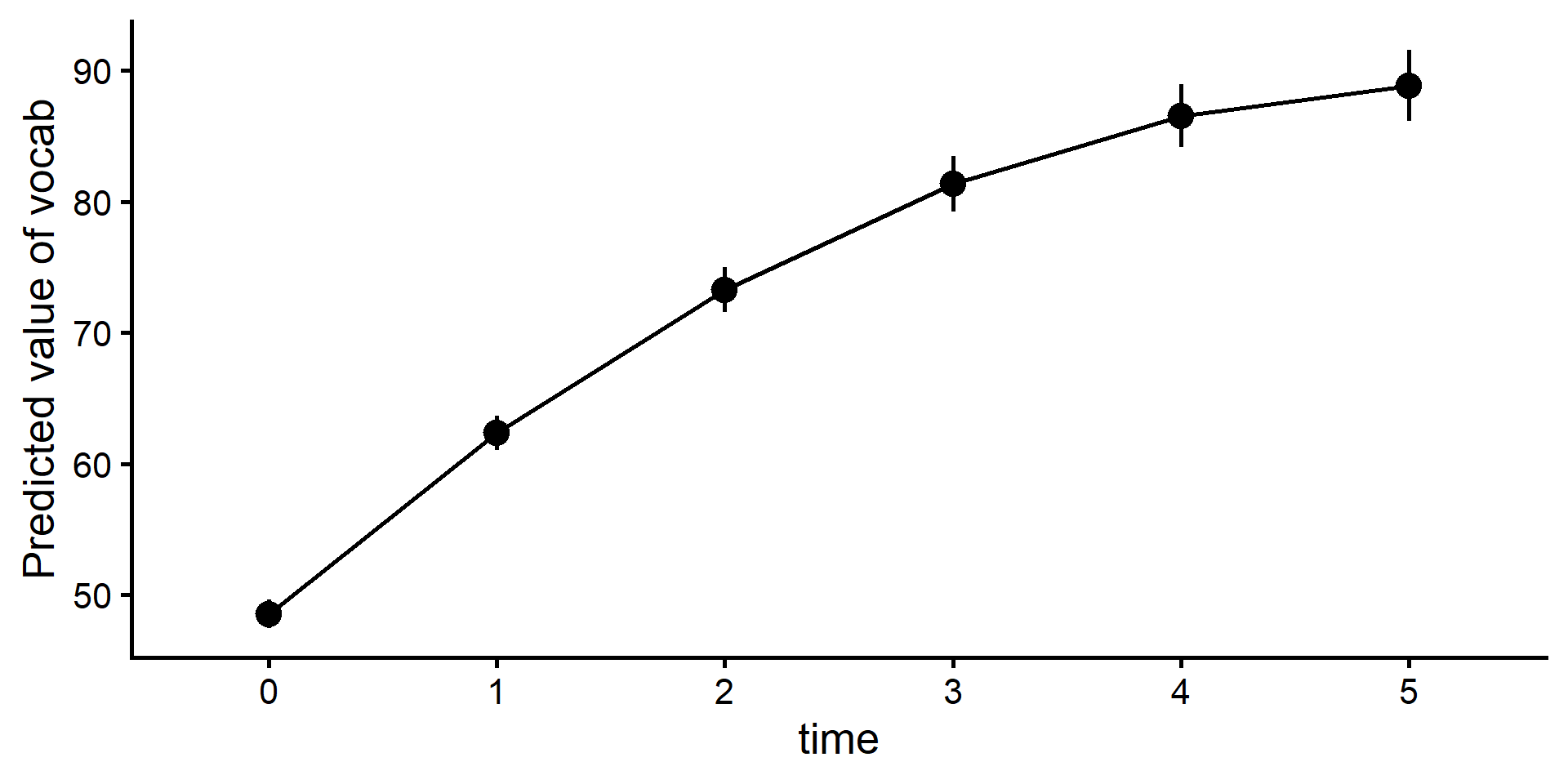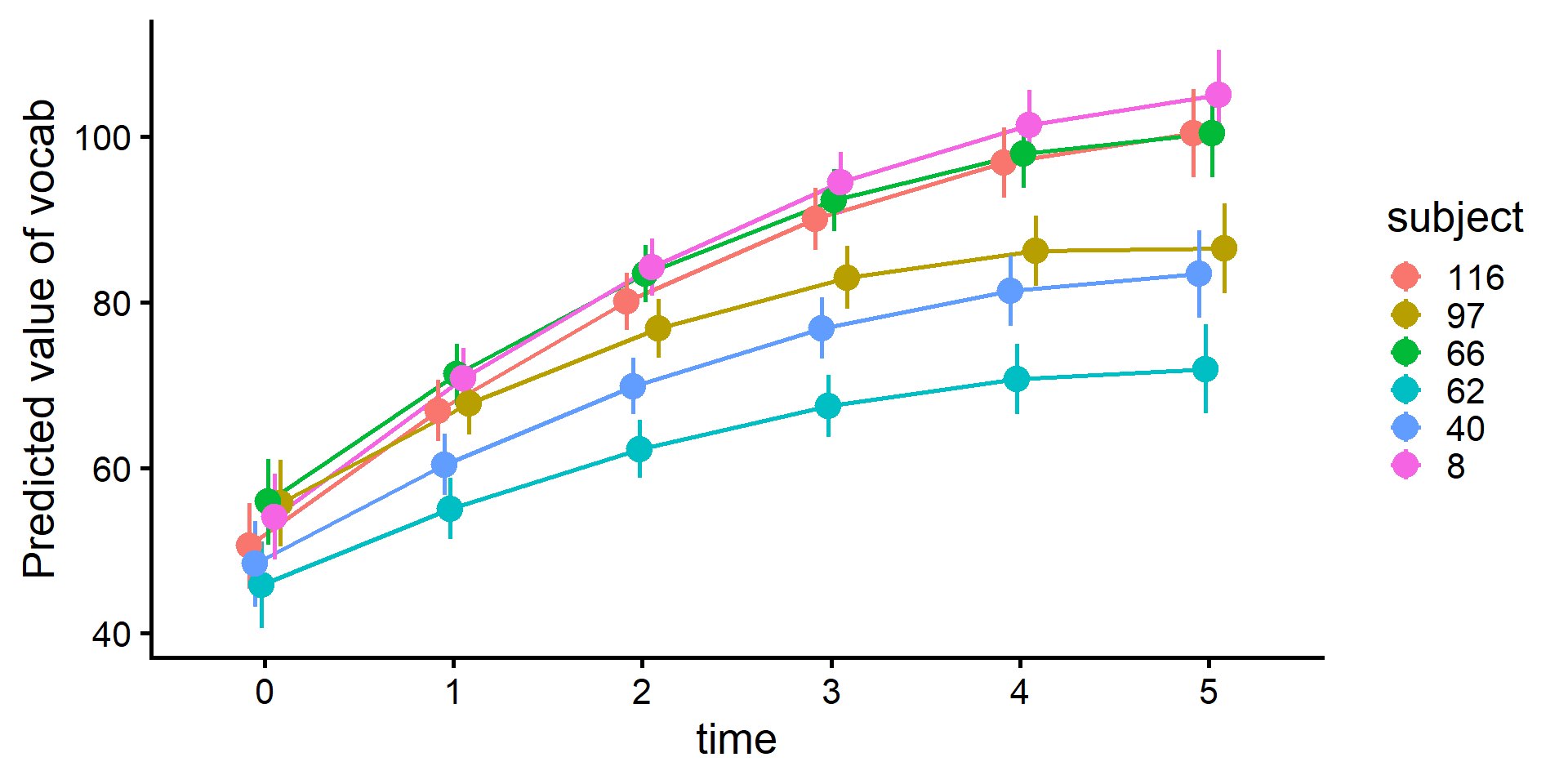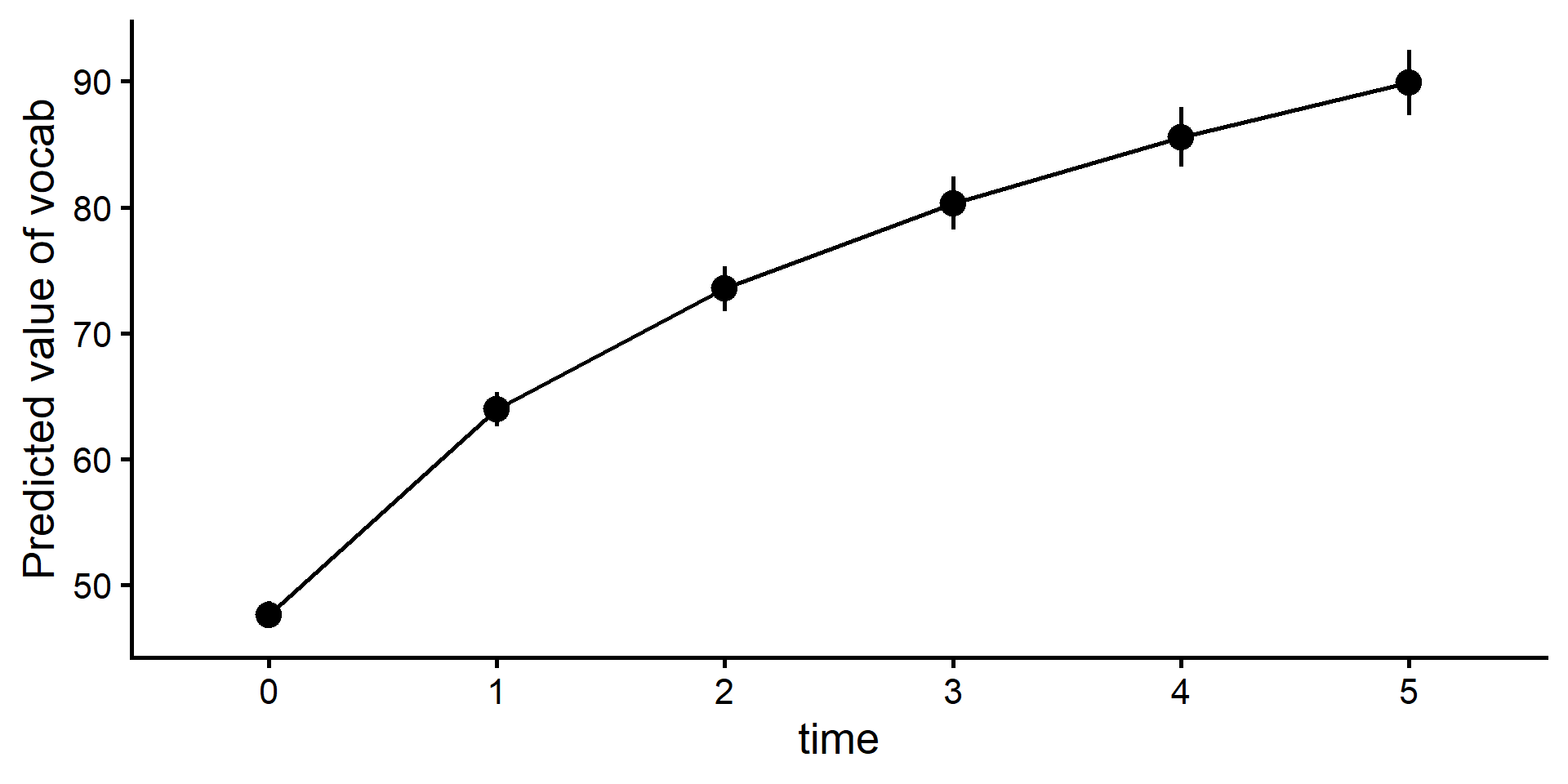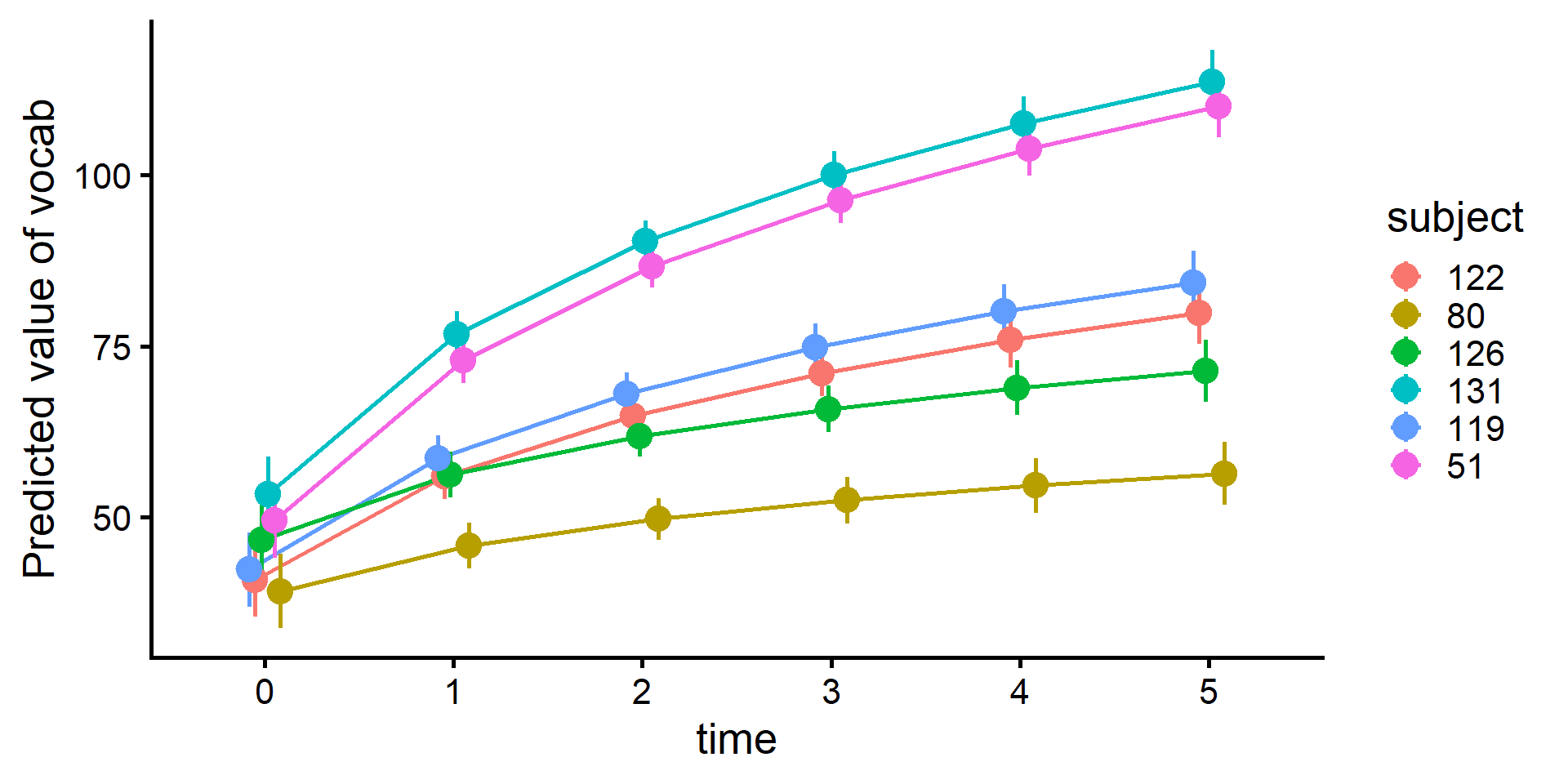
library(tidyverse)
vocab_raw <- read_csv("vocab_sim.csv")
glimpse(vocab_raw)Rows: 900
Columns: 5
$ subject <dbl> 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, …
$ program <chr> "B", "B", "B", "B", "B", "B", "A", "A", "A", "A", "A",…
$ age_months <dbl> 120, 132, 144, 156, 168, 180, 120, 132, 144, 156, 168,…
$ vocab <dbl> 45.38913, 59.32121, 72.81737, 82.83264, 88.51938, 93.2…
$ hours_read <dbl> 3.399861, 2.572877, 1.571513, 2.955250, 3.413900, 3.60…