library(tidyverse)
library(glmmTMB)
library(easystats)
vocab <- read_csv("vocab_sim.csv") |>
# Center at Baseline, scale to Years
mutate(time = (age_months - 120) / 12)
fit_log <- glmmTMB(
vocab ~ 1 + log(time + 1) + (1 + log(time + 1) | subject),
data = vocab
)Multilevel Modeling
Predicting Change
Spring 2026 | CLAS | PSYC 894
Jeffrey M. Girard | Lecture 12b

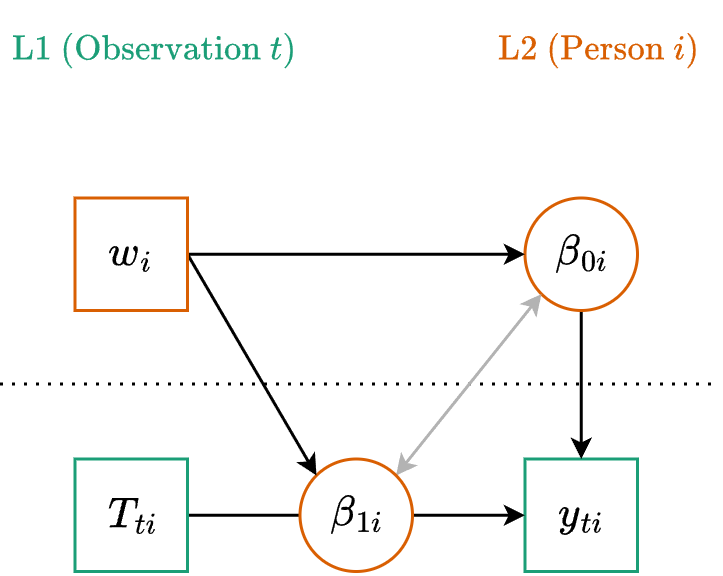
Path Diagram
Visualizing L2 Predictors
estimate_relation(fit_l2, by = c("time", "program")) |> plot()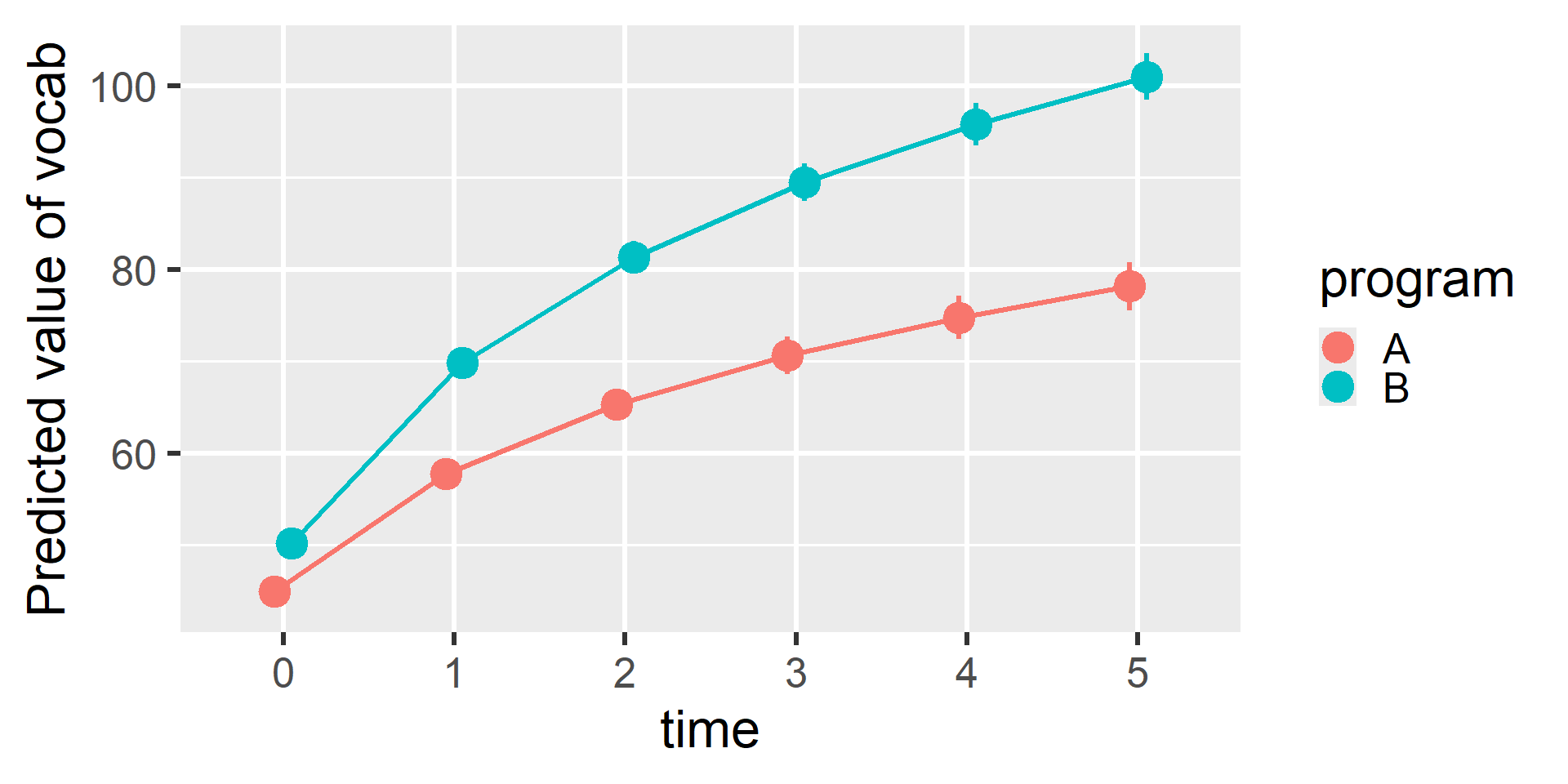
Visualizing the L1 Effect
estimate_relation(fit_combined, by = "read_w") |> plot()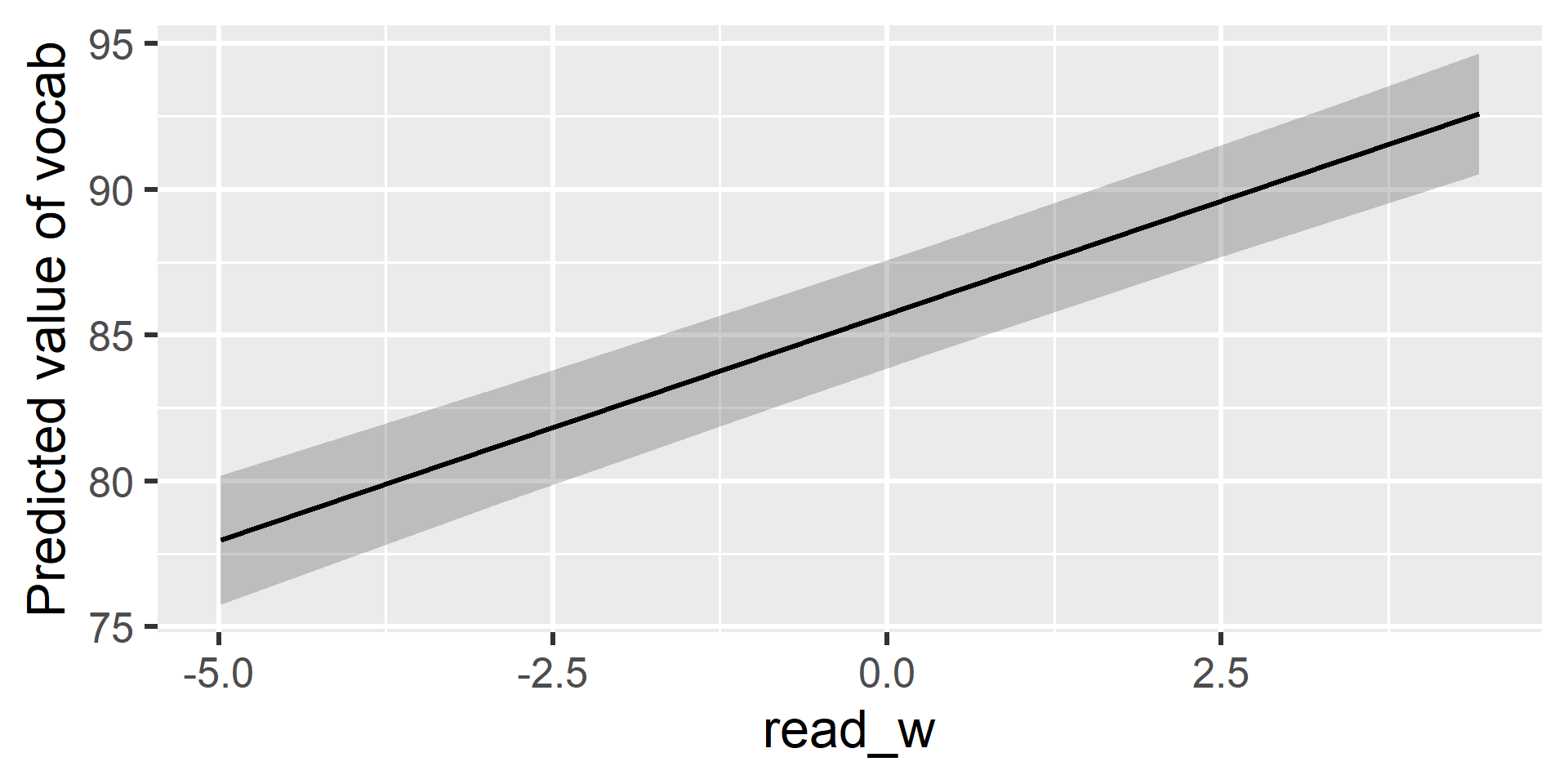
This plot shows the pure within-person effect. For every hour a child reads above their personal average, their vocabulary score is pushed upward away from their underlying growth curve.
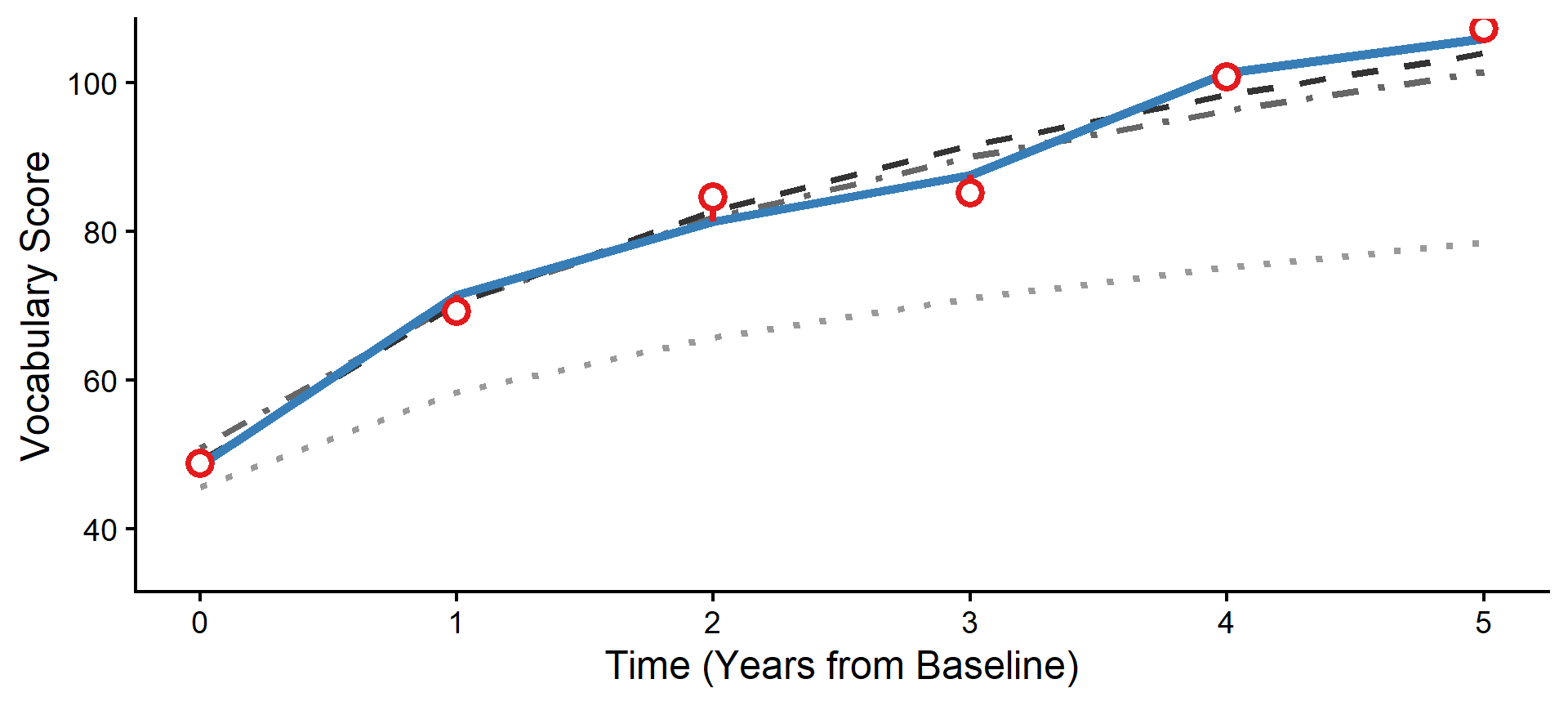
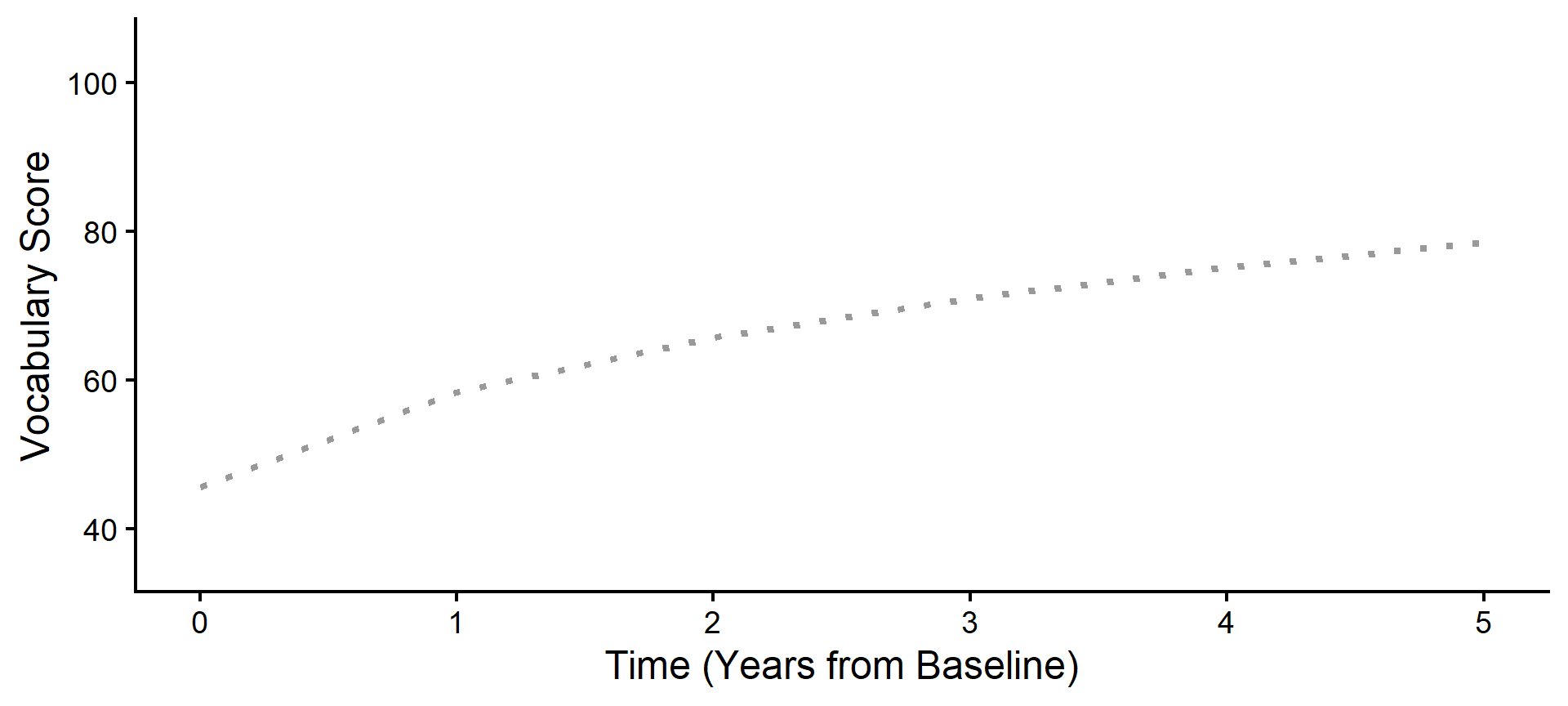
Step 1: The Baseline (Program A)
First, we plot the reference group for our model: the average trajectory for all children in Program A. If we had no predictors and just an intercept, this is where we would start.
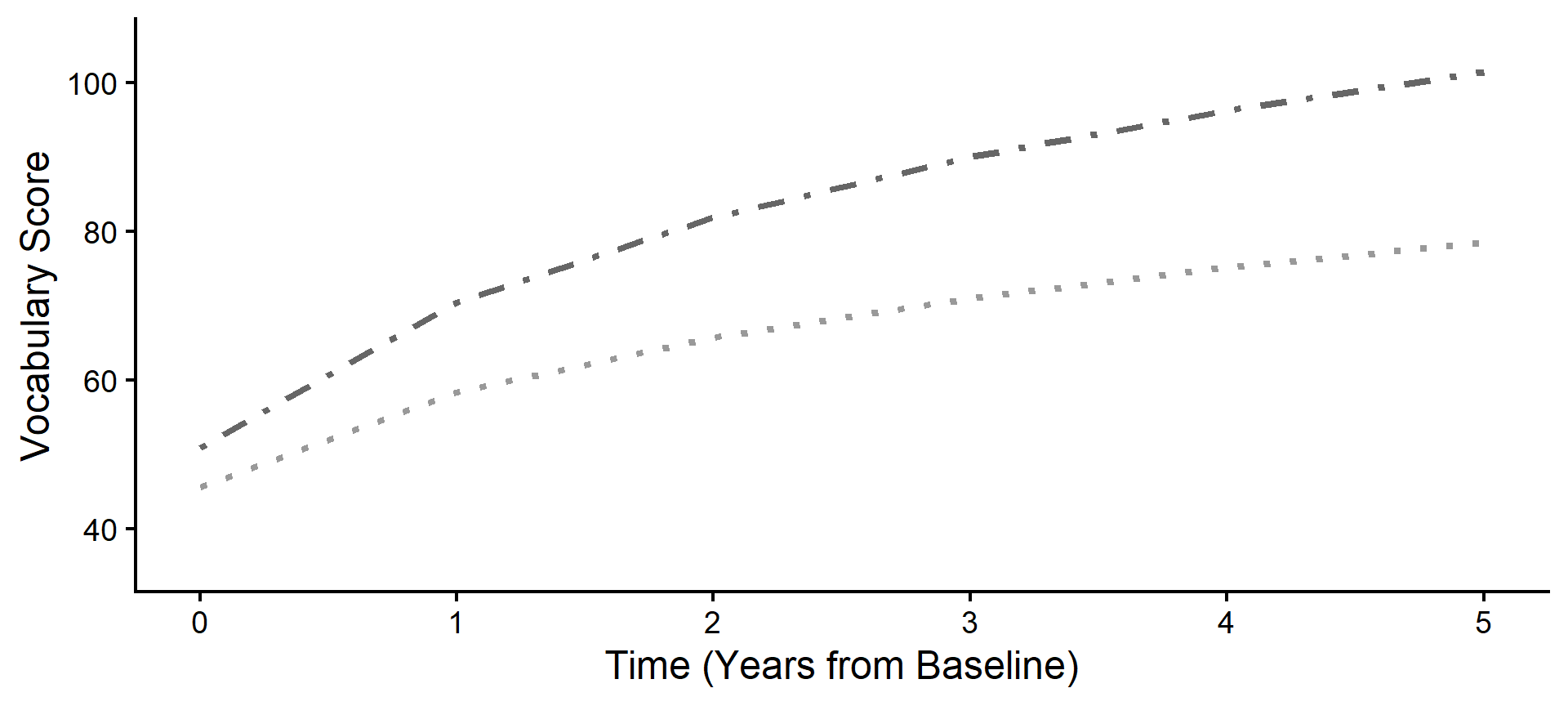
Step 2: The Level 2 Shift (Program B)
Because Subject 84 is in Program B, our model applies the fixed effect parameters (\(\gamma_{01}\) and \(\gamma_{11}\)) to shift their expected starting point up and accelerate their expected curve.
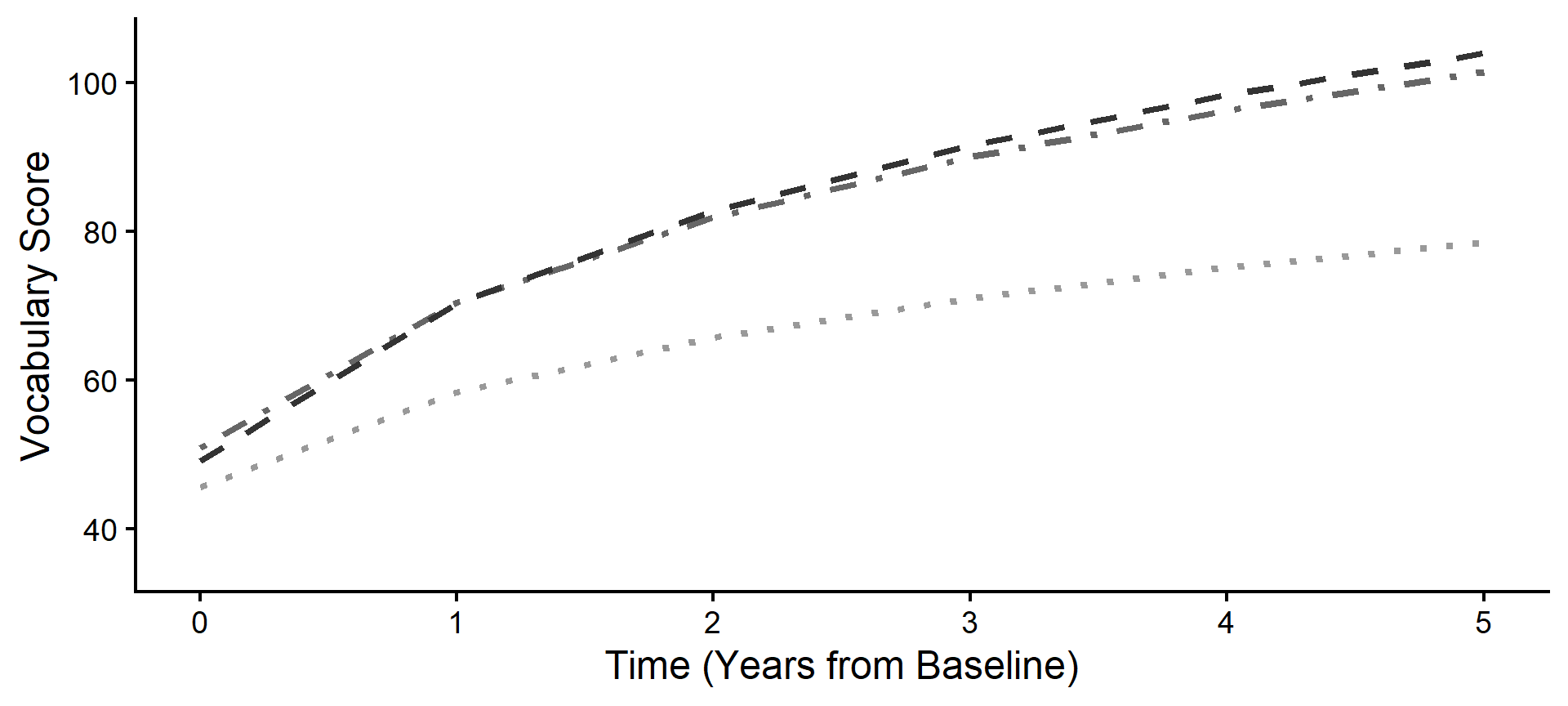
Step 3: The Individual Shift (Random)
Next, we apply Subject 84’s specific Random Effects (\(u\)). Notice how their personal trajectory shifts away from the Program B average based on their unique, individual starting point and growth rate.
Step 4: The Level 1 Adjustments
Now we apply the Level 1 fluctuations. For every year Subject 84 read more or less than their personal average, the model adjusts their expected trajectory up or down, creating a jagged line.
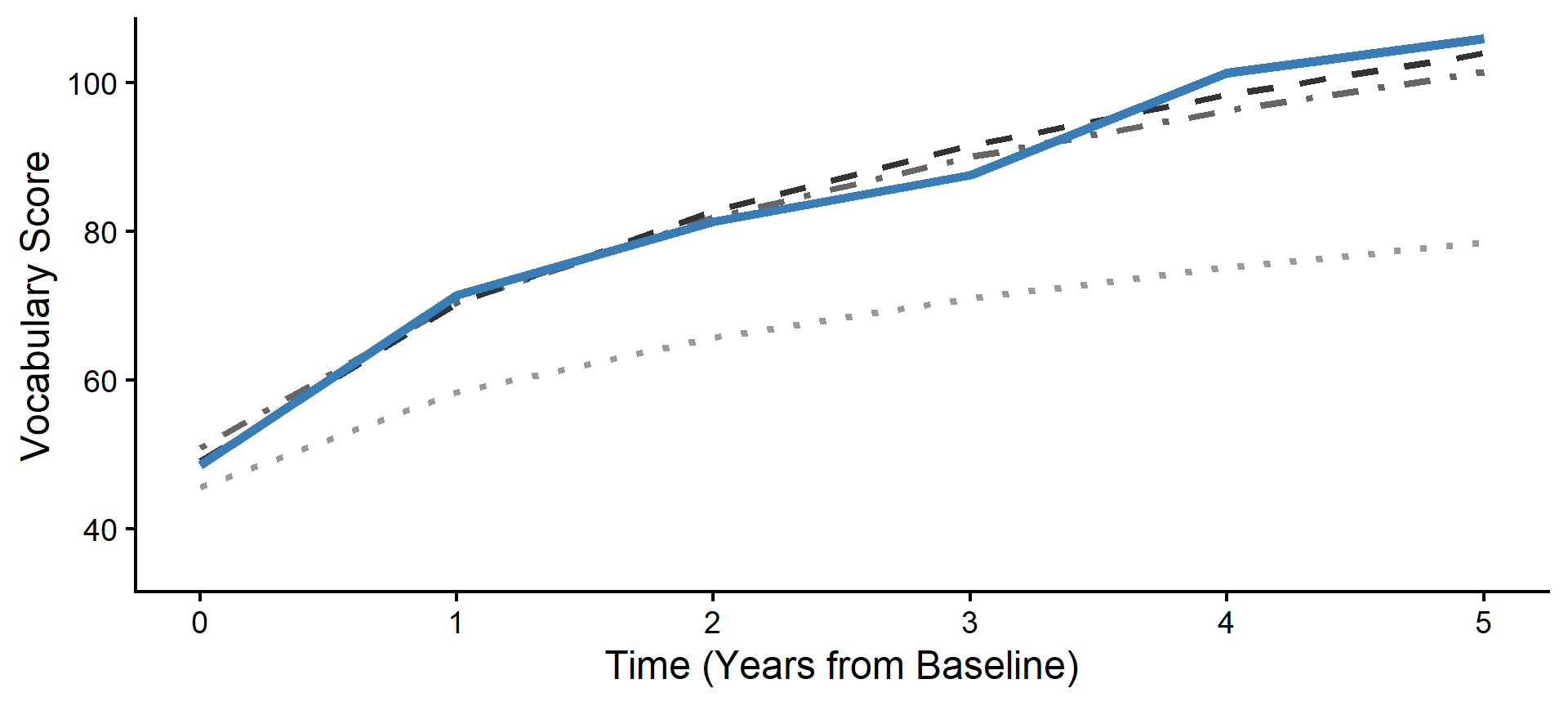
Step 5: The Observation Residuals
Finally, we plot the actual data points. The remaining distance between the jagged, fluctuation-adjusted line and the raw data points represents our final Level 1 residuals (\(e_{ti}\)).